一、简介
在本教程中,我们将探讨命令查询责任分离 (CQRS) 和事件溯源设计模式的基本概念。
虽然经常被引用为互补模式,但我们尝试分别理解它们并最终了解它们如何相互补充。有多种工具和框架(例如Axon)可帮助采用这些模式,但我们将使用 Java 创建一个简单的应用程序以了解基础知识。
2. 基本概念
在我们尝试实现它们之前,我们将首先从理论上理解这些模式。此外,由于它们很好地代表了独立的模式,我们将尝试在不混合它们的情况下理解它们。
请注意,这些模式通常在企业应用程序中一起使用。在这方面,他们还受益于其他几种企业架构模式。我们将讨论其中的一些。
2.1. 事件溯源
事件溯源为我们提供了一种将应用程序状态持久化为有序事件序列的新方法。我们可以选择性地查询这些事件,并在任何时间点重构应用程序的状态。当然,为了使这项工作有效,我们需要将应用程序状态的每个更改重新映像为事件:
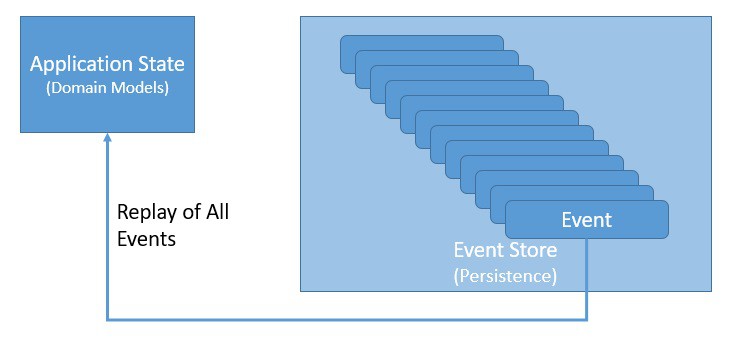
这里的这些事件是已经发生并且无法改变的事实——换句话说,它们必须是不可变的。重新创建应用程序状态只是重放所有事件的问题。
请注意,这也开启了选择性重播事件、反向重播某些事件等的可能性。因此,我们可以将应用程序状态本身视为次要公民,将事件日志作为我们的主要真实来源。
2.2. CQRS
简而言之,CQRS 是关于隔离应用程序架构的命令和查询端。CQRS 基于 Bertrand Meyer 建议的命令查询分离 (CQS) 原则。CQS 建议我们将对域对象的操作分为两个不同的类别:查询和命令:
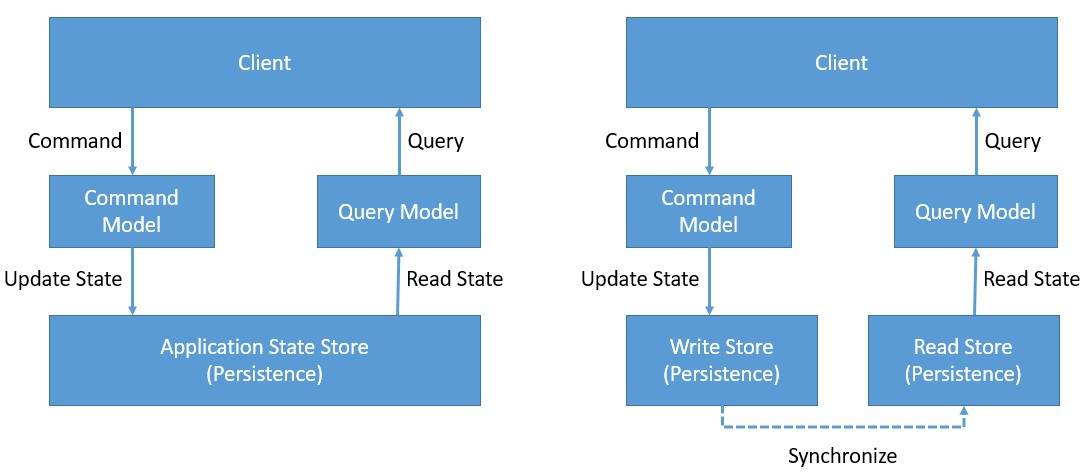
查询返回结果并且不改变系统的可观察状态。命令改变系统状态但不一定返回值。
我们通过清晰地分离域模型的命令和查询端来实现这一点。我们可以更进一步,将数据存储的写入和读取端也分开,当然,通过引入一种机制使它们保持同步。
3. 一个简单的应用
我们将从描述一个用 Java 构建域模型的简单应用程序开始。
该应用程序将在域模型上提供 CRUD 操作,还将具有域对象的持久性。CRUD 代表创建、读取、更新和删除,它们是我们可以对域对象执行的基本操作。
我们将在后面的部分中使用相同的应用程序来介绍事件溯源和 CQRS。
在此过程中,我们将在示例中利用领域驱动设计 (DDD)中的一些概念。
DDD 致力于分析和设计依赖于复杂领域特定知识的软件。它建立在软件系统需要基于一个完善的域模型的思想之上。DDD 最初由 Eric Evans 规定为模式目录。我们将使用其中一些模式来构建我们的示例。
3.1. 应用概述
创建用户配置文件并对其进行管理是许多应用程序中的典型要求。我们将定义一个简单的域模型来捕获用户配置文件以及持久性:
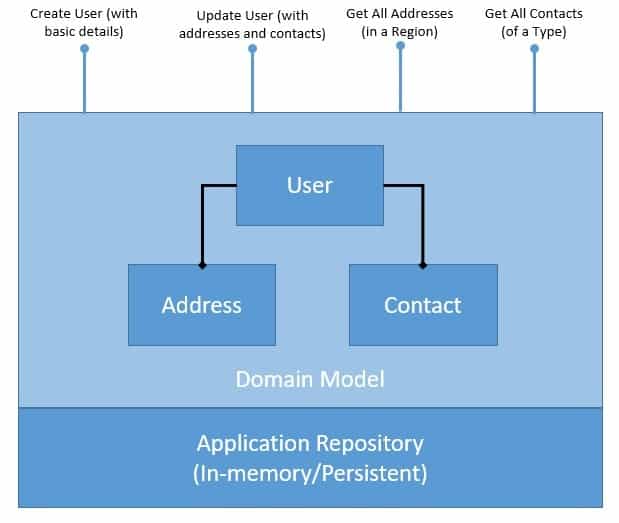
如我们所见,我们的域模型已规范化并公开了多个 CRUD 操作。这些操作仅用于演示,可简单可复杂,具体取决于要求。此外,这里的持久化存储库可以在内存中,也可以使用数据库代替。
3.2. 应用实施
首先,我们必须创建代表领域模型的 Java 类。这是一个相当简单的领域模型,甚至可能不需要像事件溯源和 CQRS 这样复杂的设计模式。但是,我们将保持简单以专注于理解基础知识:
public class User {
private String userid;
private String firstName;
private String lastName;
private Set<Contact> contacts;
private Set<Address> addresses;
// getters and setters
}
public class Contact {
private String type;
private String detail;
// getters and setters
}
public class Address {
private String city;
private String state;
private String postcode;
// getters and setters
}
此外,我们将为我们的应用程序状态的持久性定义一个简单的内存存储库。当然,这并没有增加任何价值,但足以满足我们稍后的演示:
public class UserRepository {
private Map<String, User> store = new HashMap<>();
}
现在,我们将定义一个服务来在我们的域模型上公开典型的 CRUD 操作:
public class UserService {
private UserRepository repository;
public UserService(UserRepository repository) {
this.repository = repository;
}
public void createUser(String userId, String firstName, String lastName) {
User user = new User(userId, firstName, lastName);
repository.addUser(userId, user);
}
public void updateUser(String userId, Set<Contact> contacts, Set<Address> addresses) {
User user = repository.getUser(userId);
user.setContacts(contacts);
user.setAddresses(addresses);
repository.addUser(userId, user);
}
public Set<Contact> getContactByType(String userId, String contactType) {
User user = repository.getUser(userId);
Set<Contact> contacts = user.getContacts();
return contacts.stream()
.filter(c -> c.getType().equals(contactType))
.collect(Collectors.toSet());
}
public Set<Address> getAddressByRegion(String userId, String state) {
User user = repository.getUser(userId);
Set<Address> addresses = user.getAddresses();
return addresses.stream()
.filter(a -> a.getState().equals(state))
.collect(Collectors.toSet());
}
}
这几乎就是我们设置简单应用程序所要做的。这远非生产就绪代码,但它揭示了我们将在本教程后面讨论的一些要点。
3.3. 此应用程序中的问题
在我们进一步讨论事件溯源和 CQRS 之前,有必要讨论一下当前解决方案的问题。毕竟,我们将通过应用这些模式来解决同样的问题!
在我们可能会在这里注意到的许多问题中,我们只想关注其中的两个:
- 域模型:读写操作发生在同一个域模型上。虽然这对于像这样的简单领域模型来说不是问题,但随着领域模型变得复杂,它可能会变得更糟。我们可能需要为它们优化我们的域模型和底层存储,以适应读写操作的个性化需求。
- 持久性:我们对领域对象的持久性仅存储领域模型的最新状态。虽然这对于大多数情况来说已经足够了,但它使某些任务具有挑战性。例如,如果我们必须对域对象如何更改状态执行历史审计,这在这里是不可能的。我们必须用一些审计日志来补充我们的解决方案才能实现这一点。
4. 介绍CQRS
我们将通过在我们的应用程序中引入 CQRS 模式来解决我们在上一节中讨论的第一个问题。作为其中的一部分,我们将分离域模型及其持久性以处理写入和读取操作。让我们看看 CQRS 模式如何重构我们的应用程序:
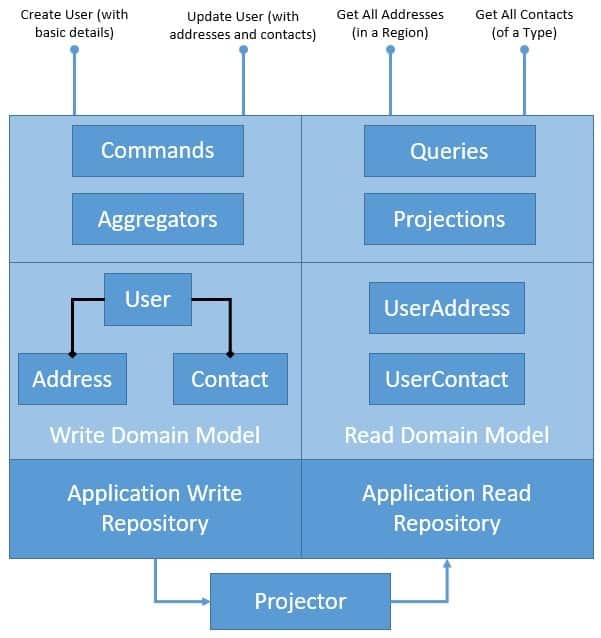
此处的图表解释了我们打算如何将我们的应用程序架构清楚地分离为写入和读取端。但是,我们在这里引入了很多我们必须更好地理解的新组件。请注意,这些与 CQRS 并不严格相关,但 CQRS 从中受益匪浅:
- 聚合/聚合器:
聚合是领域驱动设计 (DDD) 中描述的一种模式,它通过将实体绑定到聚合根来对不同的实体进行逻辑分组。聚合模式提供实体之间的事务一致性。
CQRS 自然受益于聚合模式,该模式对写入域模型进行分组,提供事务保证。聚合通常保持缓存状态以获得更好的性能,但没有它也可以完美地工作。
- 投影仪/投影仪:
投影是另一个非常有利于 CQRS 的重要模式。投影本质上意味着以不同的形状和结构来表示域对象。
这些原始数据的投影是只读的并且经过高度优化以提供增强的阅读体验。我们可能会再次决定缓存投影以获得更好的性能,但这不是必需的。
4.1. 实现应用程序的写入端
让我们首先实现应用程序的写入端。
我们将从定义所需的命令开始。命令是改变域模型状态的意图。它是否成功取决于我们配置的业务规则。
让我们看看我们的命令:
public class CreateUserCommand {
private String userId;
private String firstName;
private String lastName;
}
public class UpdateUserCommand {
private String userId;
private Set<Address> addresses;
private Set<Contact> contacts;
}
这些是非常简单的类,用于保存我们打算改变的数据。
接下来,我们定义一个聚合,负责接收命令并处理它们。聚合可以接受或拒绝命令:
public class UserAggregate {
private UserWriteRepository writeRepository;
public UserAggregate(UserWriteRepository repository) {
this.writeRepository = repository;
}
public User handleCreateUserCommand(CreateUserCommand command) {
User user = new User(command.getUserId(), command.getFirstName(), command.getLastName());
writeRepository.addUser(user.getUserid(), user);
return user;
}
public User handleUpdateUserCommand(UpdateUserCommand command) {
User user = writeRepository.getUser(command.getUserId());
user.setAddresses(command.getAddresses());
user.setContacts(command.getContacts());
writeRepository.addUser(user.getUserid(), user);
return user;
}
}
聚合使用存储库来检索当前状态并保留对其的任何更改。此外,它可以在本地存储当前状态,以避免在处理每个命令时到存储库的往返成本。
最后,我们需要一个存储库来保存领域模型的状态。这通常是数据库或其他持久存储,但在这里我们将简单地用内存中的数据结构替换它们:
public class UserWriteRepository {
private Map<String, User> store = new HashMap<>();
// accessors and mutators
}
我们的应用程序的写入端到此结束。
4.2. 实施应用程序的读取端
现在让我们切换到应用程序的读取端。我们将从定义域模型的读取端开始:
public class UserAddress {
private Map<String, Set<Address>> addressByRegion = new HashMap<>();
}
public class UserContact {
private Map<String, Set<Contact>> contactByType = new HashMap<>();
}
如果我们回想一下我们的读取操作,就不难看出这些类映射得非常好,可以很好地处理它们。这就是创建以我们拥有的查询为中心的领域模型的美妙之处。
接下来,我们将定义读取存储库。同样,我们将只使用内存中的数据结构,即使这在实际应用程序中将是更持久的数据存储:
public class UserReadRepository {
private Map<String, UserAddress> userAddress = new HashMap<>();
private Map<String, UserContact> userContact = new HashMap<>();
// accessors and mutators
}
现在,我们将定义我们必须支持的必需查询。查询是获取数据的意图——它不一定会产生数据。
让我们看看我们的查询:
public class ContactByTypeQuery {
private String userId;
private String contactType;
}
public class AddressByRegionQuery {
private String userId;
private String state;
}
同样,这些是保存数据以定义查询的简单 Java 类。
我们现在需要的是一个可以处理这些查询的投影:
public class UserProjection {
private UserReadRepository readRepository;
public UserProjection(UserReadRepository readRepository) {
this.readRepository = readRepository;
}
public Set<Contact> handle(ContactByTypeQuery query) {
UserContact userContact = readRepository.getUserContact(query.getUserId());
return userContact.getContactByType()
.get(query.getContactType());
}
public Set<Address> handle(AddressByRegionQuery query) {
UserAddress userAddress = readRepository.getUserAddress(query.getUserId());
return userAddress.getAddressByRegion()
.get(query.getState());
}
}
这里的投影使用我们之前定义的读取存储库来解决我们的查询。这也差不多结束了我们应用程序的读取端。
4.3. 同步读写数据
这个难题的一部分仍然没有解决:没有什么可以同步我们的写入和读取存储库。
这就是我们需要投影仪的地方。投影仪具有将写入域模型投影到读取域模型的逻辑。
有更复杂的方法来处理这个问题,但我们会保持相对简单:
public class UserProjector {
UserReadRepository readRepository = new UserReadRepository();
public UserProjector(UserReadRepository readRepository) {
this.readRepository = readRepository;
}
public void project(User user) {
UserContact userContact = Optional.ofNullable(
readRepository.getUserContact(user.getUserid()))
.orElse(new UserContact());
Map<String, Set<Contact>> contactByType = new HashMap<>();
for (Contact contact : user.getContacts()) {
Set<Contact> contacts = Optional.ofNullable(
contactByType.get(contact.getType()))
.orElse(new HashSet<>());
contacts.add(contact);
contactByType.put(contact.getType(), contacts);
}
userContact.setContactByType(contactByType);
readRepository.addUserContact(user.getUserid(), userContact);
UserAddress userAddress = Optional.ofNullable(
readRepository.getUserAddress(user.getUserid()))
.orElse(new UserAddress());
Map<String, Set<Address>> addressByRegion = new HashMap<>();
for (Address address : user.getAddresses()) {
Set<Address> addresses = Optional.ofNullable(
addressByRegion.get(address.getState()))
.orElse(new HashSet<>());
addresses.add(address);
addressByRegion.put(address.getState(), addresses);
}
userAddress.setAddressByRegion(addressByRegion);
readRepository.addUserAddress(user.getUserid(), userAddress);
}
}
这是一种非常粗略的方法,但可以让我们充分了解CQRS 工作所需的条件。此外,没有必要让读写存储库位于不同的实体商店。分布式系统有其自身的问题!
请注意,将写入域的当前状态投影到不同的读取域模型中并不方便。我们在此处采用的示例相当简单,因此,我们看不到问题所在。
然而,随着写入和读取模型变得越来越复杂,它会变得越来越难以预测。我们可以通过基于事件的投影而不是使用事件溯源的基于状态的投影来解决这个问题。我们将在本教程的后面部分看到如何实现这一点。
4.4. CQRS 的优点和缺点
我们讨论了 CQRS 模式并学习了如何在典型应用程序中引入它。我们明确尝试解决与域模型在处理读写方面的刚性相关的问题。
现在让我们讨论 CQRS 给应用程序架构带来的一些其他好处:
- CQRS 为我们提供了一种方便的方法来选择适合写入和读取操作的单独域模型;我们不必创建支持两者的复杂领域模型
- 它帮助我们选择适合处理复杂的读写操作的存储库,例如写入的高吞吐量和读取的低延迟
- 它通过提供关注点分离和更简单的领域模型自然地补充了分布式体系结构中基于事件的编程模型
然而,这不是免费的。从这个简单的例子可以明显看出,CQRS 给架构增加了相当大的复杂性。在许多情况下,它可能不适合或不值得痛苦:
- 只有复杂的领域模型才能从这种模式增加的复杂性中获益;一个简单的域模型可以在没有所有这些的情况下进行管理
- 在某种程度上自然会导致代码重复,与它给我们带来的好处相比,这是可以接受的恶;但是,建议个人判断
- 分离的存储库导致一致性问题,并且很难始终保持写入和读取存储库完美同步;我们经常不得不满足于最终的一致性
5. 引入事件溯源
接下来,我们将解决我们在简单应用程序中讨论的第二个问题。如果我们还记得的话,它与我们的持久性存储库有关。
我们将引入事件溯源来解决这个问题。事件溯源极大地改变了我们对应用程序状态存储的看法。
让我们看看它如何改变我们的存储库:
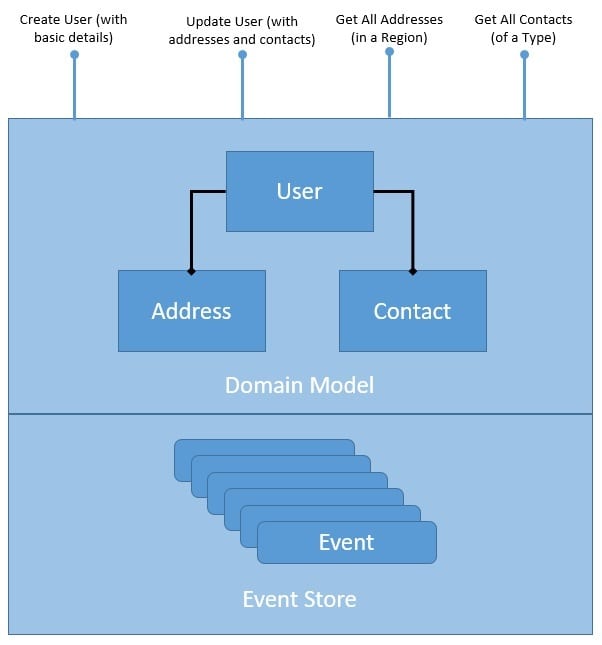
在这里,我们构建了存储库来存储有序的域事件列表。对域对象的每次更改都被视为一个事件。事件的粗粒度或细粒度是域设计的问题。这里要考虑的重要事情是事件具有时间顺序并且是不可变的。
5.1. 实施事件和事件存储
事件驱动应用程序中的基本对象是事件,事件溯源也不例外。正如我们之前看到的,事件表示域模型状态在特定时间点的特定变化。因此,我们将从为我们的简单应用程序定义基本事件开始:
public abstract class Event {
public final UUID id = UUID.randomUUID();
public final Date created = new Date();
}
这只是确保我们在应用程序中生成的每个事件都获得唯一标识和创建时间戳。这些是进一步处理它们所必需的。
当然,可能还有其他几个我们感兴趣的属性,比如确定事件来源的属性。
接下来,让我们创建一些继承自该基础事件的特定于域的事件:
public class UserCreatedEvent extends Event {
private String userId;
private String firstName;
private String lastName;
}
public class UserContactAddedEvent extends Event {
private String contactType;
private String contactDetails;
}
public class UserContactRemovedEvent extends Event {
private String contactType;
private String contactDetails;
}
public class UserAddressAddedEvent extends Event {
private String city;
private String state;
private String postCode;
}
public class UserAddressRemovedEvent extends Event {
private String city;
private String state;
private String postCode;
}
这些是 Java 中的简单 POJO,包含域事件的详细信息。但是,这里需要注意的重要一点是事件的粒度。
我们本可以为用户更新创建一个事件,但我们决定为地址和联系人的添加和删除创建单独的事件。选择被映射到使使用领域模型更有效的东西。
现在,自然地,我们需要一个存储库来保存我们的领域事件:
public class EventStore {
private Map<String, List<Event>> store = new HashMap<>();
}
这是一个简单的内存数据结构,用于保存我们的领域事件。实际上,有几种专门为处理事件数据而创建的解决方案,例如 Apache Druid。有许多能够处理事件源的通用分布式数据存储,包括Kafka和Cassandra。
5.2. 生成和消费事件
因此,现在我们处理所有 CRUD 操作的服务将发生变化。现在,它不会更新移动域状态,而是附加域事件。它还将使用相同的域事件来响应查询。
让我们看看我们如何实现这一目标:
public class UserService {
private EventStore repository;
public UserService(EventStore repository) {
this.repository = repository;
}
public void createUser(String userId, String firstName, String lastName) {
repository.addEvent(userId, new UserCreatedEvent(userId, firstName, lastName));
}
public void updateUser(String userId, Set<Contact> contacts, Set<Address> addresses) {
User user = UserUtility.recreateUserState(repository, userId);
user.getContacts().stream()
.filter(c -> !contacts.contains(c))
.forEach(c -> repository.addEvent(
userId, new UserContactRemovedEvent(c.getType(), c.getDetail())));
contacts.stream()
.filter(c -> !user.getContacts().contains(c))
.forEach(c -> repository.addEvent(
userId, new UserContactAddedEvent(c.getType(), c.getDetail())));
user.getAddresses().stream()
.filter(a -> !addresses.contains(a))
.forEach(a -> repository.addEvent(
userId, new UserAddressRemovedEvent(a.getCity(), a.getState(), a.getPostcode())));
addresses.stream()
.filter(a -> !user.getAddresses().contains(a))
.forEach(a -> repository.addEvent(
userId, new UserAddressAddedEvent(a.getCity(), a.getState(), a.getPostcode())));
}
public Set<Contact> getContactByType(String userId, String contactType) {
User user = UserUtility.recreateUserState(repository, userId);
return user.getContacts().stream()
.filter(c -> c.getType().equals(contactType))
.collect(Collectors.toSet());
}
public Set<Address> getAddressByRegion(String userId, String state) throws Exception {
User user = UserUtility.recreateUserState(repository, userId);
return user.getAddresses().stream()
.filter(a -> a.getState().equals(state))
.collect(Collectors.toSet());
}
}
请注意,我们正在生成几个事件作为处理更新用户操作的一部分。此外,值得注意的是,我们如何通过重放迄今为止生成的所有域事件来生成域模型的当前状态。
当然,在实际应用中,这不是一个可行的策略,我们必须维护一个本地缓存以避免每次都生成状态。事件存储库中还有其他策略(如快照和汇总)可以加快该过程。
我们在我们的简单应用程序中引入事件溯源的努力到此结束。
5.3. 事件溯源的优点和缺点
现在我们已经成功地采用了另一种使用事件源来存储域对象的方法。事件溯源是一种强大的模式,如果使用得当,它可以为应用程序架构带来很多好处:
- 由于不需要读取、更新和写入,使写入操作更快;write 只是将事件附加到日志
- 消除了对象关系阻抗,从而消除了对复杂映射工具的需求;当然,我们仍然需要重新创建对象
- 碰巧提供审计日志作为副产品,完全可靠;我们可以准确地调试领域模型的状态是如何改变的
- 它使得支持时间查询和实现时间旅行(过去某一点的域状态)成为可能!
- 它非常适合在微服务架构中设计松散耦合的组件,这些组件通过交换消息进行异步通信
然而,一如既往,即使是事件溯源也不是灵丹妙药。它确实迫使我们采用截然不同的方式来存储数据。这在某些情况下可能没有用:
- 采用事件溯源需要相关的学习曲线和思维方式的转变;首先,这并不直观
- 这使得处理典型查询变得相当困难,因为我们需要重新创建状态,除非我们将状态保存在本地缓存中
- 虽然它可以应用于任何领域模型,但它更适合事件驱动架构中基于事件的模型
6. 事件溯源的 CQRS
现在我们已经了解了如何将事件溯源和 CQRS 分别引入到我们的简单应用程序中,是时候将它们组合在一起了。现在应该相当直观,这些模式可以极大地相互受益。但是,我们将在本节中使其更加明确。
让我们首先看看应用程序架构如何将它们组合在一起:
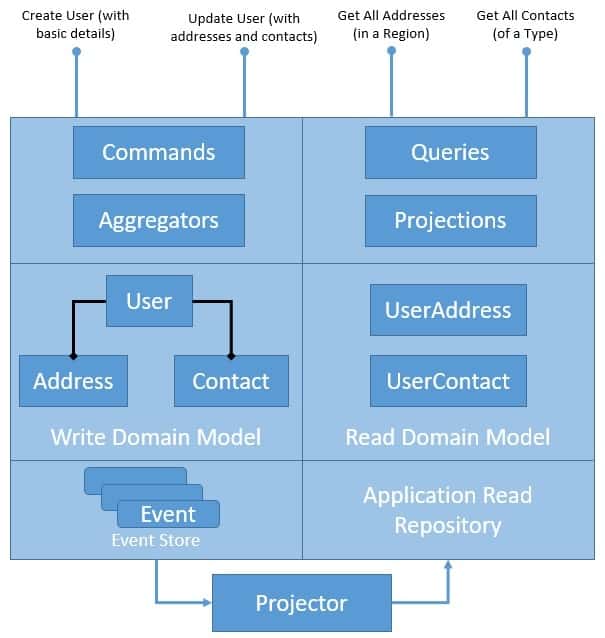
现在这应该不足为奇了。我们已将存储库的写入端替换为事件存储,而存储库的读取端仍然相同。
请注意,这不是在应用程序架构中使用事件溯源和 CQRS 的唯一方法。我们可以非常有创意,将这些模式与其他模式结合使用,并提出多种架构选项。
这里重要的是确保我们使用它们来管理复杂性,而不是简单地进一步增加复杂性!
6.1. 将 CQRS 和事件溯源结合在一起
分别实施事件溯源和 CQRS 后,不难理解我们如何将它们组合在一起。
我们将从引入 CQRS 的应用程序开始,并进行相关更改以将事件溯源纳入其中。我们还将利用我们在引入事件溯源的应用程序中定义的相同事件和事件存储。
只有一些变化。我们将首先更改聚合以生成事件而不是更新状态:
public class UserAggregate {
private EventStore writeRepository;
public UserAggregate(EventStore repository) {
this.writeRepository = repository;
}
public List<Event> handleCreateUserCommand(CreateUserCommand command) {
UserCreatedEvent event = new UserCreatedEvent(command.getUserId(),
command.getFirstName(), command.getLastName());
writeRepository.addEvent(command.getUserId(), event);
return Arrays.asList(event);
}
public List<Event> handleUpdateUserCommand(UpdateUserCommand command) {
User user = UserUtility.recreateUserState(writeRepository, command.getUserId());
List<Event> events = new ArrayList<>();
List<Contact> contactsToRemove = user.getContacts().stream()
.filter(c -> !command.getContacts().contains(c))
.collect(Collectors.toList());
for (Contact contact : contactsToRemove) {
UserContactRemovedEvent contactRemovedEvent = new UserContactRemovedEvent(contact.getType(),
contact.getDetail());
events.add(contactRemovedEvent);
writeRepository.addEvent(command.getUserId(), contactRemovedEvent);
}
List<Contact> contactsToAdd = command.getContacts().stream()
.filter(c -> !user.getContacts().contains(c))
.collect(Collectors.toList());
for (Contact contact : contactsToAdd) {
UserContactAddedEvent contactAddedEvent = new UserContactAddedEvent(contact.getType(),
contact.getDetail());
events.add(contactAddedEvent);
writeRepository.addEvent(command.getUserId(), contactAddedEvent);
}
// similarly process addressesToRemove
// similarly process addressesToAdd
return events;
}
}
唯一需要的其他更改是在投影仪中,它现在需要处理事件而不是域对象状态:
public class UserProjector {
UserReadRepository readRepository = new UserReadRepository();
public UserProjector(UserReadRepository readRepository) {
this.readRepository = readRepository;
}
public void project(String userId, List<Event> events) {
for (Event event : events) {
if (event instanceof UserAddressAddedEvent)
apply(userId, (UserAddressAddedEvent) event);
if (event instanceof UserAddressRemovedEvent)
apply(userId, (UserAddressRemovedEvent) event);
if (event instanceof UserContactAddedEvent)
apply(userId, (UserContactAddedEvent) event);
if (event instanceof UserContactRemovedEvent)
apply(userId, (UserContactRemovedEvent) event);
}
}
public void apply(String userId, UserAddressAddedEvent event) {
Address address = new Address(
event.getCity(), event.getState(), event.getPostCode());
UserAddress userAddress = Optional.ofNullable(
readRepository.getUserAddress(userId))
.orElse(new UserAddress());
Set<Address> addresses = Optional.ofNullable(userAddress.getAddressByRegion()
.get(address.getState()))
.orElse(new HashSet<>());
addresses.add(address);
userAddress.getAddressByRegion()
.put(address.getState(), addresses);
readRepository.addUserAddress(userId, userAddress);
}
public void apply(String userId, UserAddressRemovedEvent event) {
Address address = new Address(
event.getCity(), event.getState(), event.getPostCode());
UserAddress userAddress = readRepository.getUserAddress(userId);
if (userAddress != null) {
Set<Address> addresses = userAddress.getAddressByRegion()
.get(address.getState());
if (addresses != null)
addresses.remove(address);
readRepository.addUserAddress(userId, userAddress);
}
}
public void apply(String userId, UserContactAddedEvent event) {
// Similarly handle UserContactAddedEvent event
}
public void apply(String userId, UserContactRemovedEvent event) {
// Similarly handle UserContactRemovedEvent event
}
}
如果我们回想一下我们在处理基于状态的投影时讨论的问题,这就是一个潜在的解决方案。
基于事件的投影比较方便,也比较容易实现。我们所要做的就是处理所有发生的域事件并将它们应用于所有读取的域模型。通常,在基于事件的应用程序中,投影仪会监听它感兴趣的域事件,而不依赖于直接调用它的人。
这几乎是我们在我们的简单应用程序中将事件溯源和 CQRS 结合在一起所要做的全部工作。
七、总结
在本教程中,我们讨论了事件溯源和 CQRS 设计模式的基础知识。我们开发了一个简单的应用程序并将这些模式单独应用于它。
在这个过程中,我们了解了它们带来的优势和它们带来的缺点。最后,我们了解了为什么以及如何将这两种模式合并到我们的应用程序中。
我们在本教程中讨论的简单应用程序甚至无法证明需要 CQRS 和事件溯源。我们的重点是理解基本概念,因此,这个例子很简单。但如前所述,这些模式的好处只能在具有相当复杂的域模型的应用程序中实现。
与往常一样,本教程的完整源代码可在GitHub上获得。
Post Directory
