一、简介
SEDA,即 Staged Event-Driven Architecture,是 Matt Welsh 在他的博士论文中提出的一种架构风格。论文。它的主要优点是可扩展性、对高并发流量的支持和可维护性。
在本教程中,我们将使用 SEDA 使用两个独立的实现来计算句子中的唯一单词:Spring Integration和Apache Camel。
2. 这个
SEDA 解决了几个特定于在线服务的非功能性需求:
- 高并发:架构必须支持尽可能多的并发请求。
- 动态内容:软件系统必须经常支持复杂的业务用例,需要许多步骤来处理用户请求并生成响应。
- 负载的鲁棒性:在线服务的用户流量是不可预测的,架构需要优雅地处理流量的变化。
为了满足这些需求,SEDA 将复杂的服务分解为事件驱动的阶段。这些阶段与队列间接连接,因此可以完全相互解耦。此外,每个阶段都有一个扩展机制来应对其传入负载:
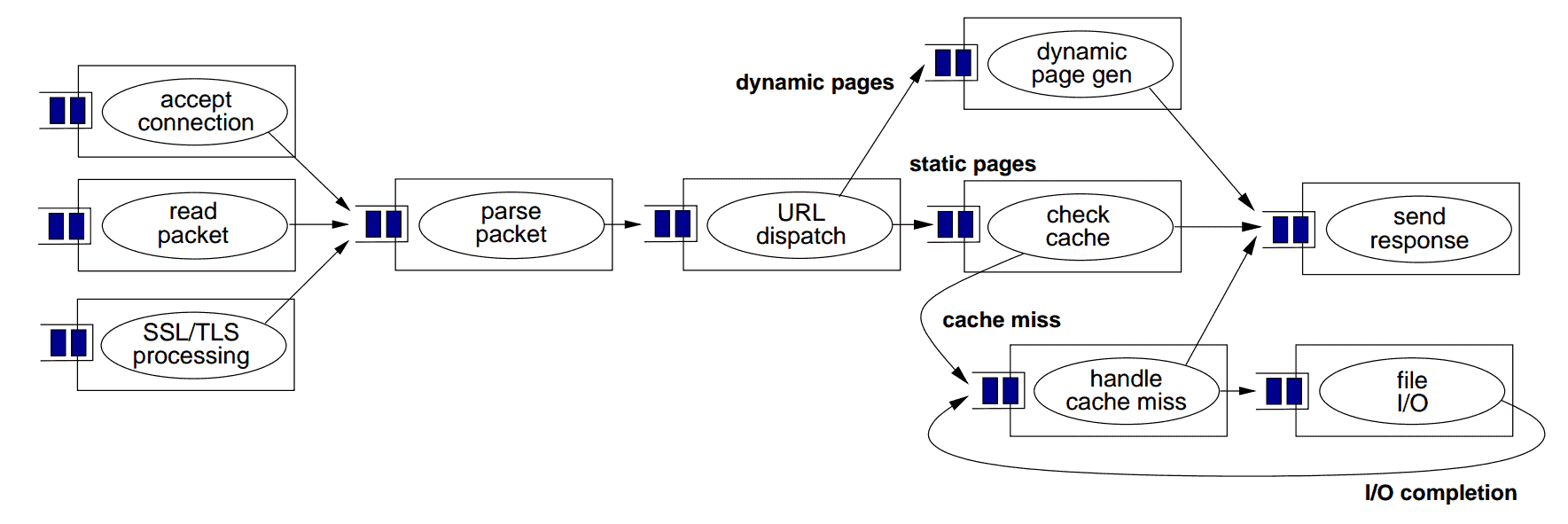
上图来自 Matt Welsh 的论文,描述了使用 SEDA 实现的 Web 服务器的整体结构。每个矩形代表传入 HTTP 请求的单个处理阶段。这些阶段可以独立地使用来自其传入队列的任务,进行一些处理或 I/O 工作,然后将消息传递到下一个队列。
2.1. 成分
为了更好地理解 SEDA 的组成部分,让我们看一下 Matt Welsh 论文中的这张图表如何显示单个阶段的内部工作原理:
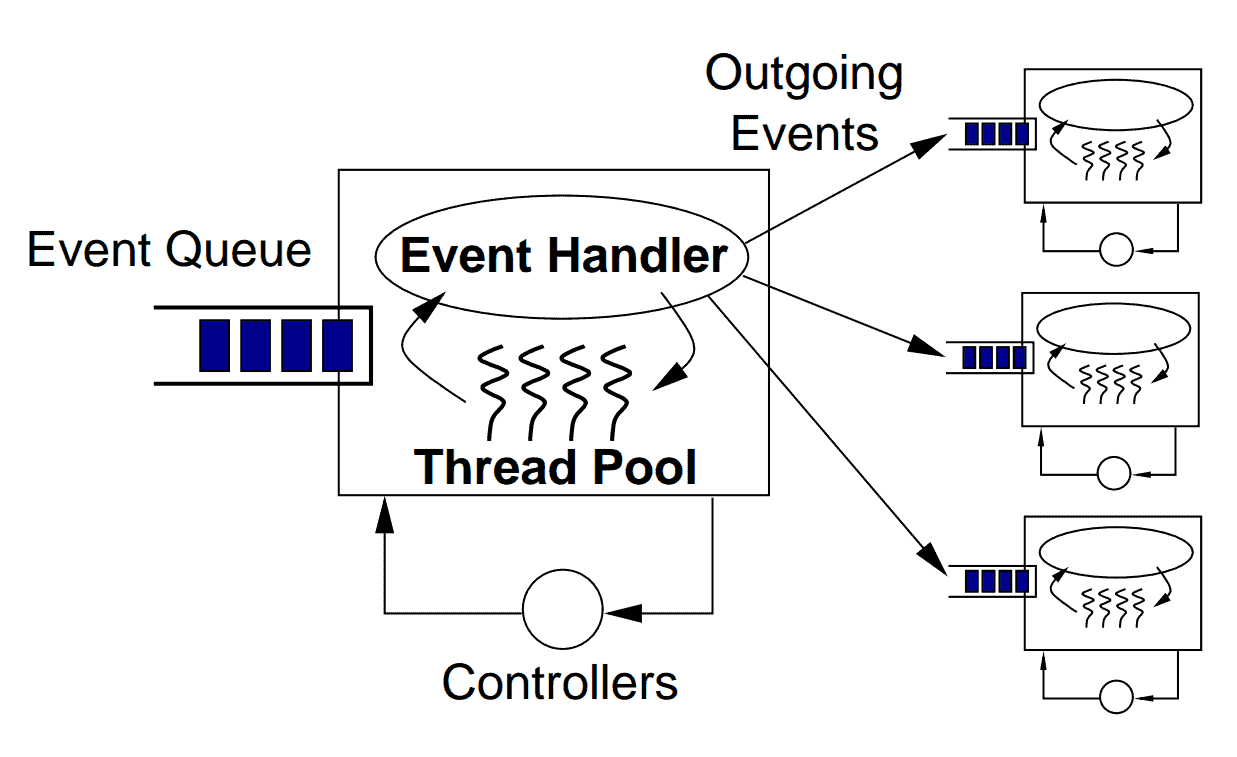
正如我们所见,每个 SEDA 阶段都有以下组件:
- 事件: 事件是包含阶段执行其处理所需的任何数据的数据结构。例如,对于 HTTP Web 服务器,事件可能包含用户数据(例如正文、标头和请求参数)和基础设施数据(例如用户 IP、请求时间戳等)。
- 事件队列:它保存着阶段的传入事件。
- 事件处理程序:事件处理程序是阶段的过程逻辑。这可能是一个简单的路由阶段,将数据从其事件队列转发到其他相关事件队列,或者是一个更复杂的以某种方式处理数据的阶段。事件处理程序可以单独或成批读取事件——后者在批处理有性能优势时很有用,例如使用一个查询更新多个数据库记录。
- 传出事件:基于业务用例和流程的整体结构,每个阶段都可以将新事件发送到零个或多个事件队列。创建和发送传出消息是在事件处理程序方法中完成的。
- 线程池:线程是一种众所周知的并发机制。在 SEDA 中,线程是针对每个阶段进行本地化和定制的。也就是说,每个阶段维护一个线程池。因此,与每个请求一个线程模型不同,每个用户请求都由 SEDA 下的多个线程处理。该模型允许我们根据其复杂性独立调整每个阶段。
- 控制器:SEDA 控制器是管理线程池大小、事件队列大小、调度等资源消耗的任何机制。控制器负责 SEDA 的弹性行为。一个简单的控制器可能会管理每个线程池中的活动线程数。更复杂的控制器可以实现复杂的性能调整算法,在运行时监控整个应用程序并调整各种参数。此外,控制器将性能调整逻辑与业务逻辑分离。这种关注点分离使我们的代码更容易维护。
通过将所有这些组件放在一起,SEDA 提供了一个强大的解决方案来处理高流量和波动的流量负载。
3.样本问题
在接下来的部分中,我们将创建两个实现来使用 SEDA 解决相同的问题。
我们的示例问题将很简单:计算每个单词在给定字符串中出现多少次不区分大小写。
让我们将单词定义为不带空格的字符序列,我们将忽略标点符号等其他复杂情况。我们的输出将是一个映射,其中包含作为键的单词和作为值的计数。例如,给定输入“我的名字是 Hesam ”,输出将是:
{
"my": 1,
"name": 1,
"is": 1,
"hesam": 1
}
3.1. 使问题适应 SEDA
让我们从 SEDA 阶段来看我们的问题。由于可扩展性是 SEDA 的核心目标,因此通常最好设计专注于特定操作的小阶段,尤其是当我们有 I/O 密集型任务时。此外,小阶段有助于我们更好地调整每个阶段的规模。
为了解决我们的字数统计问题,我们可以通过以下阶段实施解决方案:

现在我们有了阶段设计,让我们在接下来的部分中使用两种不同的企业集成技术来实现它。在此表中,我们可以预览 SEDA 将如何出现在我们的实施中:
| SEDA 组件 | 弹簧集成 | 阿帕奇骆驼 |
|---|---|---|
事件 |
org.springframework.messaging.消息 | org.apache.camel.Exchange |
事件队列 |
org.springframework.integration.channel | URI 字符串定义的端点 |
事件处理器 |
功能接口实例 | Camel 处理器、Camel 实用程序类和Function s |
线程池 |
TaskExecutor的Spring抽象 | SEDA 端点中的开箱即用支持 |
4. 使用 Spring Integration 的解决方案
对于我们的第一个实现,我们将使用 Spring Integration。Spring Integration 建立在 Spring 模型之上以支持流行的企业集成模式。
Spring Integration 包含三个主要组件:
-
消息是包含标题和正文的数据结构。
-
通道将消息从一个端点传送到另一个端点。
Spring Integration中有两种通道:
- 点对点:只有一个端点可以使用该通道中的消息。
- 发布-订阅:多个端点可以消费此通道中的消息。
-
端点将消息路由到执行某些业务逻辑的应用程序组件。Spring Integration 中有多种端点,例如转换器、路由器、服务激活器和过滤器。
让我们看一下我们的 Spring Integration 解决方案的概述:

4.1. 依赖关系
让我们开始为Spring Integration、 Spring Boot Test和Spring Integration Test添加依赖项:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-integration</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
4.2. 消息网关
消息传递网关是一种代理,它隐藏了将消息发送到集成流的复杂性。让我们为我们的 Spring Integration 流程设置一个:
@MessagingGateway
public interface IncomingGateway {
@Gateway(requestChannel = "receiveTextChannel", replyChannel = "returnResponseChannel")
public Map<String, Long> countWords(String input);
}
稍后,我们将能够使用此网关方法来测试我们的整个流程:
incomingGateway.countWords("My name is Hesam");
Spring 将“My name is Hesam”输入包装在org.springframework.messaging.Message实例中,并将其传递给receiveTextChannel,然后从returnResponseChannel给我们最终结果。
4.3. 消息通道
在本节中,我们将了解如何设置网关的初始消息通道receiveTextChannel。
在 SEDA 下,通道需要通过关联的线程池进行扩展,所以让我们从创建线程池开始:
@Bean("receiveTextChannelThreadPool")
TaskExecutor receiveTextChannelThreadPool() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(1);
executor.setMaxPoolSize(5);
executor.setThreadNamePrefix("receive-text-channel-thread-pool");
executor.initialize();
return executor;
}
接下来,我们将使用我们的线程池来创建我们的频道:
@Bean(name = "receiveTextChannel")
MessageChannel getReceiveTextChannel() {
return MessageChannels.executor("receive-text", receiveTextChannelThreadPool)
.get();
}
MessageChannels是一个 Spring Integration 类,可以帮助我们创建各种类型的通道。在这里,我们使用executor()方法创建一个 ExecutorChannel,这是一个由线程池管理的通道。
我们其他的通道和线程池的设置方式同上。
4.4. 接收文本阶段
随着我们的渠道的建立,我们可以开始实施我们的阶段。让我们创建我们的初始阶段:
@Bean
IntegrationFlow receiveText() {
return IntegrationFlows.from(receiveTextChannel)
.channel(splitWordsChannel)
.get();
}
IntegrationFlows是一个流畅的 Spring Integration API,用于创建 IntegrationFlow对象,代表我们流程的各个阶段。from()方法配置我们阶段的传入通道, channel()配置传出通道。
在此示例中,我们的阶段将网关的输入消息传递给splitWordsChannel。此阶段在生产应用程序中可能更复杂且 I/O 密集,从持久队列或通过网络读取消息。
4.5. 分词阶段
我们的下一阶段有一个单一的职责:将我们的输入字符串拆分为 句子中各个单词的字符串数组:
@Bean
IntegrationFlow splitWords() {
return IntegrationFlows.from(splitWordsChannel)
.transform(splitWordsFunction)
.channel(toLowerCaseChannel)
.get();
}
除了我们之前使用的from()和channel()调用之外,这里我们还使用transform(),它将提供的Function应用于我们的输入消息。我们的 splitWordsFunction实现非常简单:
final Function<String, String[]> splitWordsFunction = sentence -> sentence.split(" ");
4.6. 转换为小写阶段
这个阶段将我们的String数组中的每个单词转换为小写:
@Bean
IntegrationFlow toLowerCase() {
return IntegrationFlows.from(toLowerCaseChannel)
.split()
.transform(toLowerCase)
.aggregate(aggregatorSpec -> aggregatorSpec.releaseStrategy(listSizeReached)
.outputProcessor(buildMessageWithListPayload))
.channel(countWordsChannel)
.get();
}
我们在这里使用的第一个新的IntegrationFlows方法是split()。split()方法使用拆分器模式将输入消息的每个元素 作为单独的消息发送到toLowerCase 。
我们看到的下一个新方法是aggregate(),它实现了聚合器模式。 聚合器模式有两个基本参数:
- 发布策略,决定何时将消息组合成一条消息
- 处理器,它决定如何将消息组合成一条消息
我们的发布策略函数使用 listSizeReached,它告诉聚合器在收集完输入数组的所有元素后开始聚合:
final ReleaseStrategy listSizeReached = r -> r.size() == r.getSequenceSize();
然后buildMessageWithListPayload处理器将我们的小写结果打包到一个List 中:
final MessageGroupProcessor buildMessageWithListPayload = messageGroup ->
MessageBuilder.withPayload(messageGroup.streamMessages()
.map(Message::getPayload)
.toList())
.build();
4.7. 数词阶段
我们的最后阶段将我们的单词计数打包到一个Map中,其中键是来自原始输入的单词,值是每个单词的出现次数:
@Bean
IntegrationFlow countWords() {
return IntegrationFlows.from(countWordsChannel)
.transform(convertArrayListToCountMap)
.channel(returnResponseChannel)
.get();
}
在这里,我们使用convertArrayListToCountMap函数将计数打包为Map:
final Function<List<String>, Map<String, Long>> convertArrayListToCountMap = list -> list.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
4.8. 测试我们的流程
我们可以将初始消息传递给我们的网关方法来测试我们的流程:
public class SpringIntegrationSedaIntegrationTest {
@Autowired
TestGateway testGateway;
@Test
void givenTextWithCapitalAndSmallCaseAndWithoutDuplicateWords_whenCallingCountWordOnGateway_thenWordCountReturnedAsMap() {
Map<String, Long> actual = testGateway.countWords("My name is Hesam");
Map<String, Long> expected = new HashMap<>();
expected.put("my", 1L);
expected.put("name", 1L);
expected.put("is", 1L);
expected.put("hesam", 1L);
assertEquals(expected, actual);
}
}
5. Apache Camel 解决方案
Apache Camel 是一种流行且功能强大的开源集成框架。它基于四个主要概念:
- Camel 上下文:Camel 运行时将不同的部分粘在一起。
- 路由:路由决定了消息应该如何处理以及下一步应该去哪里。
- 处理器:这些是各种企业集成模式的即用型实现。
- 组件:组件是通过 JMS、HTTP、文件 IO 等方式集成外部系统的扩展点。
Apache Camel 有一个专用于 SEDA 功能的组件,可以直接构建 SEDA 应用程序。
5.1. 依赖关系
让我们为Apache Camel 和Apache Camel Test添加所需的 Maven 依赖项:
<dependencies>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-core</artifactId>
<version>3.18.0</version>
</dependency>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-test-junit5</artifactId>
<version>3.18.0</version>
<scope>test</scope>
</dependency>
</dependencies>
5.2. 定义 SEDA 端点
首先,我们需要定义端点。端点是用 URI 字符串定义的组件。SEDA 端点必须以“ seda:[endpointName] ”开头:
static final String receiveTextUri = "seda:receiveText?concurrentConsumers=5";
static final String splitWordsUri = "seda:splitWords?concurrentConsumers=5";
static final String toLowerCaseUri = "seda:toLowerCase?concurrentConsumers=5";
static final String countWordsUri = "seda:countWords?concurrentConsumers=5";
static final String returnResponse = "mock:result";
正如我们所见,每个端点都配置为有五个并发消费者。这相当于每个端点最多有 5 个线程。
为了进行测试,returnResponse是一个模拟端点。
5.3. 扩展RouteBuilder
接下来,让我们定义一个扩展 Apache Camel 的RouteBuilder并覆盖其 configure() 方法的类。此类连接所有 SEDA 端点:
public class WordCountRoute extends RouteBuilder {
@Override
public void configure() throws Exception {
}
}
在以下部分中,我们将使用从RouteBuilder继承的便捷方法向此configure()方法添加行来定义我们的阶段。
5.4. 接收文本阶段
此阶段从 SEDA 端点接收消息并将它们路由到下一阶段而不进行任何处理:
from(receiveTextUri).to(splitWordsUri);
在这里,我们使用继承的 from()方法指定传入端点,并使用 to()设置传出端点。
5.5. 分词阶段
让我们实现将输入文本拆分为单个单词的阶段:
from(splitWordsUri)
.transform(ExpressionBuilder.bodyExpression(s -> s.toString().split(" ")))
.to(toLowerCaseUri);
transform()方法将我们的Function 应用于我们的输入消息,将其拆分为一个数组。
5.6. 转换为小写阶段
我们的下一个任务是将输入中的每个单词转换为小写。因为我们需要将我们的转换函数应用于消息中的每个 字符串而不是数组本身,所以我们将使用split()方法来拆分输入消息以进行处理,然后将结果聚合回ArrayList:
from(toLowerCaseUri)
.split(body(), new ArrayListAggregationStrategy())
.transform(ExpressionBuilder.bodyExpression(body -> body.toString().toLowerCase()))
.end()
.to(countWordsUri);
end()方法标志着拆分过程的结束。一旦列表中的每个项目都被转换,Apache Camel 应用我们指定的聚合策略ArrayListAggregationStrategy 。
ArrayListAggregationStrategy扩展了 Apache Camel 的AbstractListAggregationStrategy来定义应该聚合消息的哪一部分。在这种情况下,消息正文是新小写的单词:
class ArrayListAggregationStrategy extends AbstractListAggregationStrategy<String> {
@Override
public String getValue(Exchange exchange) {
return exchange.getIn()
.getBody(String.class);
}
}
5.7. 数词阶段
最后一个阶段使用转换器将数组转换为单词到单词计数的映射:
from(countWordsUri)
.transform(ExpressionBuilder.bodyExpression(List.class, body -> body.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()))))
.to(returnResponse);
5.8. 测试我们的路线
让我们测试一下我们的路线:
public class ApacheCamelSedaIntegrationTest extends CamelTestSupport {
@Test
public void givenTextWithCapitalAndSmallCaseAndWithoutDuplicateWords_whenSendingTextToInputUri_thenWordCountReturnedAsMap()
throws InterruptedException {
Map<String, Long> expected = new HashMap<>();
expected.put("my", 1L);
expected.put("name", 1L);
expected.put("is", 1L);
expected.put("hesam", 1L);
getMockEndpoint(WordCountRoute.returnResponse).expectedBodiesReceived(expected);
template.sendBody(WordCountRoute.receiveTextUri, "My name is Hesam");
assertMockEndpointsSatisfied();
}
@Override
protected RoutesBuilder createRouteBuilder() throws Exception {
RoutesBuilder wordCountRoute = new WordCountRoute();
return wordCountRoute;
}
}
CamelTestSupport超类提供了许多字段和方法来帮助我们测试流程。我们使用getMockEndpoint()和expectedBodiesReceived()来设置我们的预期结果,并使用 template.sendBody()将测试数据提交到我们的模拟端点。最后,我们使用assertMockEndpointsSatisfied()来测试我们的期望是否与实际结果相符。
六,总结
在本文中,我们了解了 SEDA 及其组件和用例。之后,我们探讨了如何使用 SEDA 解决同样的问题,首先使用 Spring Integration,然后使用 Apache Camel。
与往常一样,本教程的完整源代码可在GitHub上获得。
Post Directory
