一、概述
在本教程中,我们将说明如何使部署在OpenShift中的应用程序保持健康。
2. 什么是健康应用?
首先,让我们尝试了解保持应用程序健康的含义。
Pod 中的应用程序经常会遇到问题。特别是,应用程序可能会停止响应或开始不正确地响应。
应用程序可能会由于临时问题而变得不健康,例如配置错误或与数据库、存储或其他应用程序等外部组件的连接。
构建弹性应用程序的第一步是对 pod 实施自动健康检查。如果出现问题,Pod 将自动重启,无需人工干预。
3. 使用探针进行健康检查
Kubernetes 和 OpenShift 提供两种类型的探测器:活性探测器和就绪探测器。
我们使用 liveness probes 来了解何时需要重新启动容器。当运行状况检查失败并且 pod 变得不可用时,OpenShift 会重新启动 pod。
就绪探测 验证容器接受流量的可用性。当所有容器都准备就绪时,我们认为 pod 就绪。当 Pod 未处于就绪状态时,服务负载均衡器会移除 Pod。
如果容器需要很长时间才能启动,该机制允许我们将连接路由到准备好接受所需流量的 pod。例如,当需要初始化数据集或建立与另一个容器或外部服务的连接时,就会发生这种情况。
我们可以通过两种方式配置 liveness probe:
- 编辑 pod 部署文件
- 使用 OpenShift 向导
在这两种情况下,获得的结果都是一样的。第一种机制直接继承自 Kubernetes,已在另一篇教程中讨论过。
相反,在本教程中,我们展示了如何使用 OpenShift 图形用户界面配置探测器。
4. Liveness Probes
我们将 liveness 探测器定义为部署配置文件中特定容器的参数。pod 内的所有容器都将继承此配置。
如果探测器已创建为HTTP 或 TCP 检查,探测器将从运行容器的节点执行。当探针创建为脚本时,OpenShift 会在容器内执行探针。
因此,让我们向部署在 OpenShift 中的应用程序添加一个新的活性探测器:
- 我们选择应用所属的项目
- 在左侧面板中,我们可以单击Applications -> Deployments
- 让我们选择所选的应用程序
- 在 Application Deployment Configuration 选项卡中,我们选择Add Health Checks 警报中的链接。只有在没有为应用程序配置健康检查的情况下才会出现警报
- 在新页面中,让我们选择Add Liveness Probe
- 然后,让我们根据自己的喜好配置 liveliness probe:
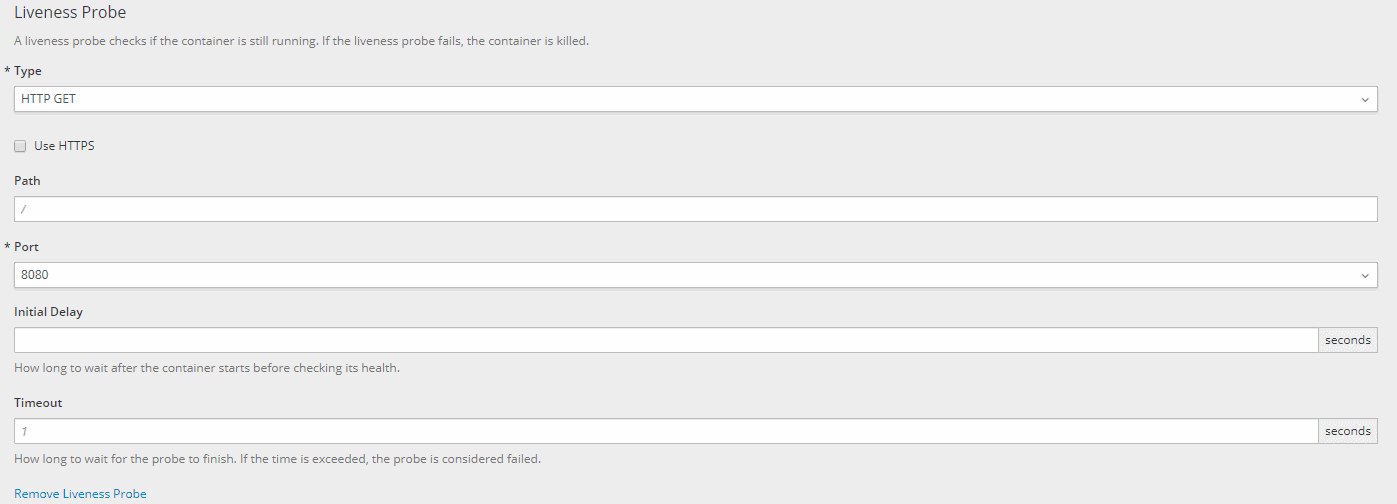
让我们分解一下这些 Liveness Probe 设置的含义:
- Type:健康检查的类型。我们可以在 HTTP(S) 检查、容器执行检查或套接字检查之间进行选择
- 使用 HTTPS:仅当通过 HTTPS 公开活动服务时才选中此复选框
- Path : 应用程序暴露 liveness probe 的路径
- Port:应用程序在其上公开 liveness probe 的端口
- Initial Delay :容器启动后到执行探测前的秒数——如果留空,则默认为0
- Timeout:检测到探测超时后的秒数——如果为空则默认为 1 秒
OpenShift 为应用程序创建一个新的DeploymentConfig。新的DeploymentConfig将包含新配置的探测器的定义。
5. 就绪探测
我们可以配置就绪探测以确保容器在被视为活动之前已准备好接收流量。与 liveness probe 不同的是,如果容器未通过就绪检查,该容器将保持活动状态但无法为流量提供服务。
就绪探测器对于执行零停机部署至关重要。
与 liveness 探针的情况一样,我们可以使用 OpenShift 向导或直接编辑 pod 部署文件来配置 readiness 探针。
由于我们已经配置了 liveness 探测器,现在让我们配置 readiness 探测器:
- 选择应用所属的项目
- 在左侧面板中,我们可以单击Applications -> Deployments
- 让我们选择所选的应用程序
- 在 Application Deployment Configuration 选项卡中,我们可以单击右上角的Actions按钮,然后选择Edit Health Checks
- 在新页面中,让我们选择添加就绪探测器
- 然后,让我们根据自己的喜好配置就绪探针:
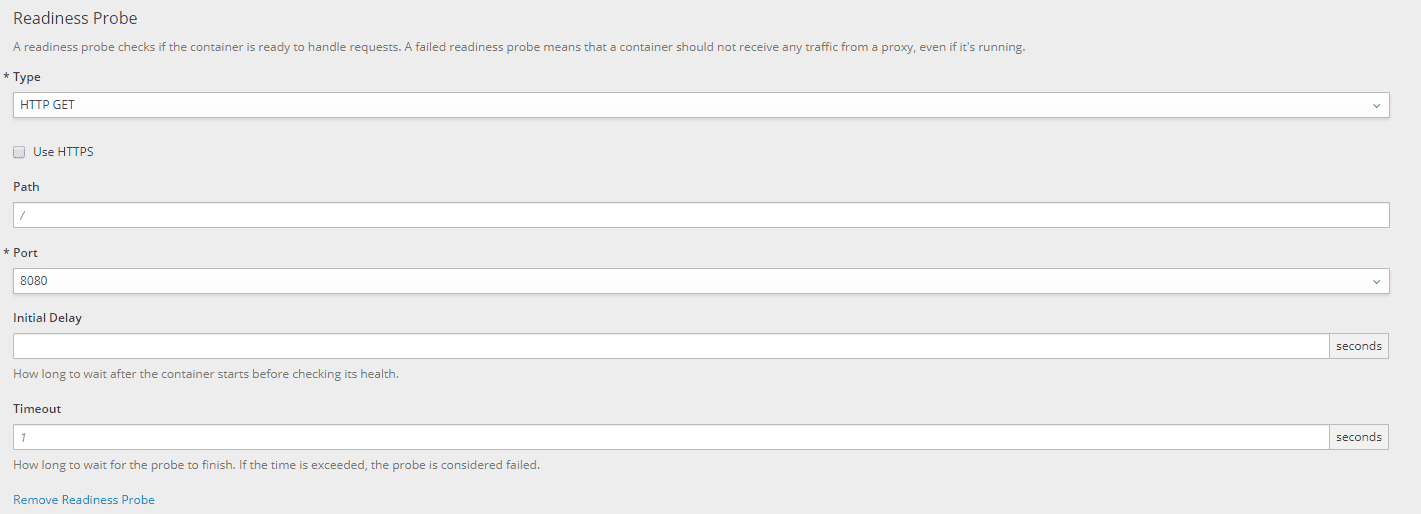
如 liveness probe 所示,可配置的参数如下:
- Type:健康检查的类型。我们可以在 HTTP(S) 检查、容器执行检查或套接字检查之间进行选择
- 使用 HTTPS:仅当准备服务在 HTTPS 中公开时才选中该复选框
- Path:应用程序公开就绪探针的路径
- Port:应用程序在其上公开就绪探针的端口
- Initial Delay :容器启动后到探测执行前的秒数(默认为0)
- Timeout:检测到探测超时后的秒数(默认为 1)
同样,OpenShift 为我们的应用程序创建了一个新的DeploymentConfig(包含就绪探测器)。
6. 总结
是时候测试我们展示的内容了。假设我们有一个 Spring Boot 应用程序要部署在 OpenShift 集群中。为此,我们可以参考我们的教程,其中将测试应用程序呈现为逐步部署。
正确部署应用程序后,我们可以按照前面段落中介绍的内容开始设置探测器。Spring Boot 应用程序使用 Spring Boot Actuator 来公开健康检查端点。我们可以在我们的专门教程中找到有关配置执行器的更多信息。
在设置结束时,部署配置页面将显示有关新配置的探测器的信息:
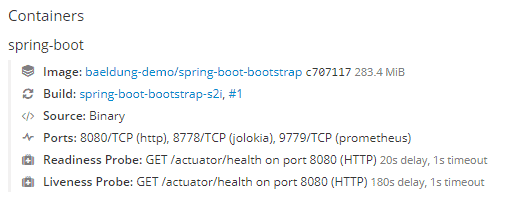
现在是时候检查就绪和活性探测器是否正常工作了。
6.1. 测试就绪探针
让我们尝试模拟新版本应用程序的部署。就绪探测器允许我们以零停机时间进行部署。这样的话,当我们部署一个新版本时,OpenShift 会创建一个新版本对应的新 pod。旧 pod 将继续为流量提供服务,直到新 pod 准备好接收流量——即直到新 pod 的就绪探测返回肯定结果。
从我们项目页面内的 OpenShift 仪表板,如果我们查看部署阶段的中间,我们可以看到零停机部署的表示:
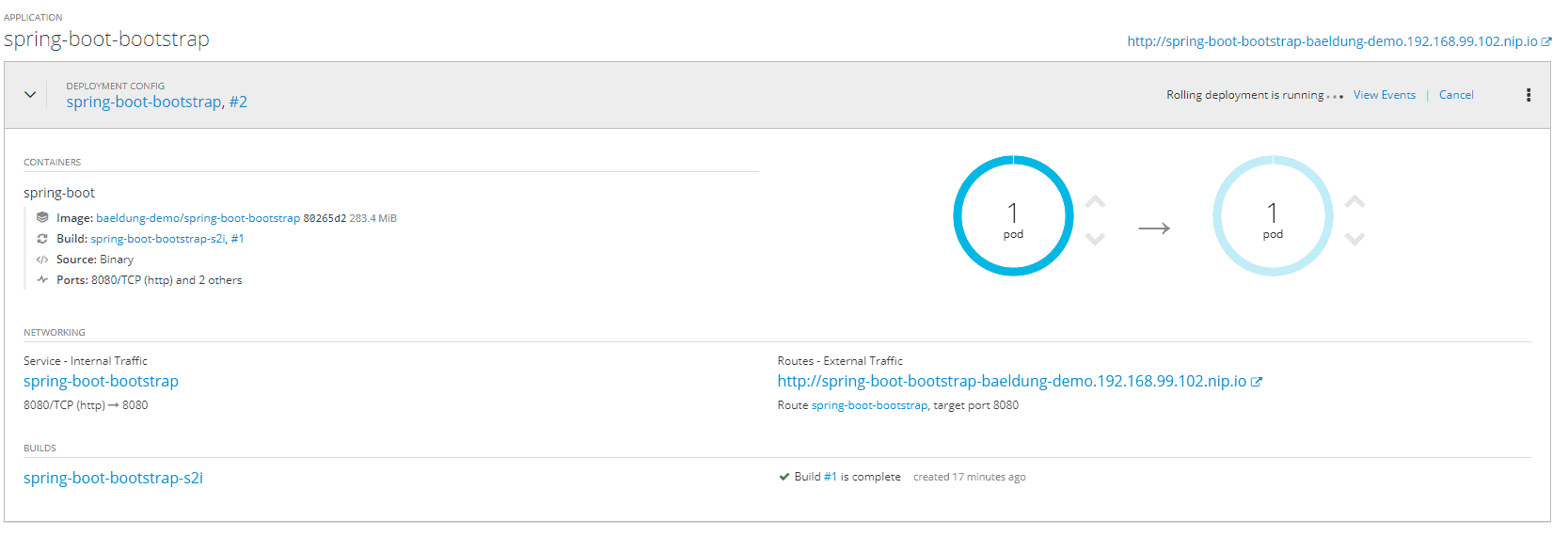
6.2. 测试 Liveness Probe
让我们来模拟 liveness probe 的失败。
假设此时应用程序执行的健康检查将返回否定结果。这表明 Pod 工作所需的资源不可用。
OpenShift 将终止 pod n次(默认情况下,n设置为 3)并重新创建它。如果问题在此阶段得到解决,则 pod 将恢复到其健康状态。否则,如果相关资源在尝试期间继续不可用,OpenShift 会认为 pod 处于失败状态。
让我们验证一下这个行为。让我们打开包含与 pod 相关的事件列表的页面。我们应该看到类似于以下屏幕的屏幕:
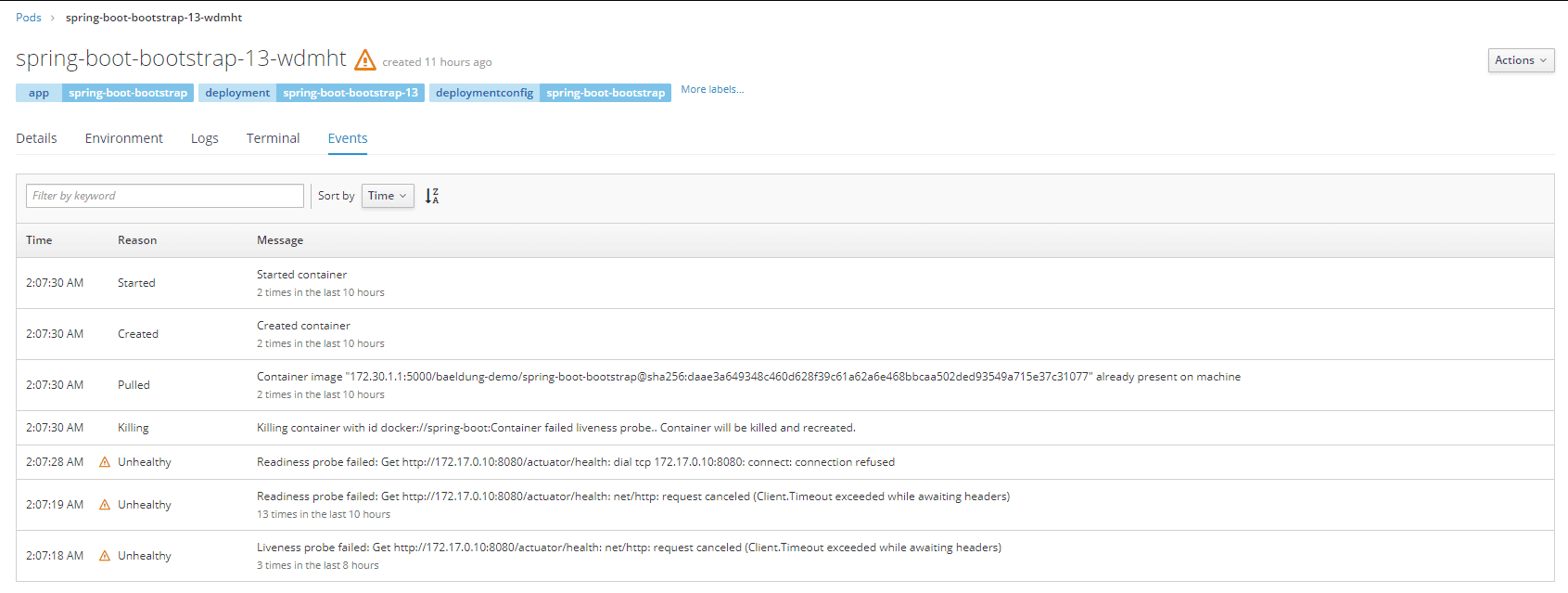
正如我们所见,OpenShift 记录了健康检查失败,杀死了 pod,并尝试重新启动它。
七、总结
在本教程中,我们探索了 OpenShift 的两种类型的探测器。
我们在同一个容器中并行使用就绪和活跃度探测器。我们使用它们来确保 OpenShift 在出现问题时重新启动容器,并且在它们尚未准备好服务时不允许流量到达它们。
与往常一样,本教程的完整源代码可在GitHub上获得。
Post Directory
