1. 简介
在本文中,我们将探索Failsafe库,并了解如何将其引入到我们的代码中,以使其更能应对故障情况。
2. 什么是容错?
无论我们的应用程序构建得多么好,总会有出错的情况。通常,这些情况是我们无法控制的-例如,调用不可用的远程服务。因此,我们必须构建能够容忍这些故障并为用户提供最佳体验的应用程序。
我们可以用许多不同的方式应对这些故障,具体取决于我们正在做什么以及出了什么问题。例如,如果我们调用一个我们知道会间歇性中断的远程服务,我们可以重试并希望调用成功。或者我们可以尝试调用提供相同功能的其他服务。
还有一些方法来构建我们的代码以避免这些情况。例如,限制对同一远程服务的并发调用数量将减少其负载。
3. 依赖
在我们可以使用Failsafe之前,我们需要在我们的构建中包含最新版本,在撰写本文时是3.3.2。
如果我们使用Maven,我们可以将其包含在pom.xml中:
<dependency>
<groupId>dev.failsafe</groupId>
<artifactId>failsafe</artifactId>
<version>3.3.2</version>
</dependency>
或者如果使用Gradle,我们可以将其包含在build.gradle中:
implementation("dev.failsafe:failsafe:3.3.2")
此时,我们已准备好开始在我们的应用程序中使用它。
4. 使用Failsafe执行操作
Failsafe与策略概念协同工作,每项策略都会确定是否将该操作视为失败以及如何对此做出反应。
4.1 确定失败
默认情况下,如果策略抛出任何异常,则该操作将被视为失败。但是,我们可以将策略配置为仅处理我们感兴趣的一组异常,无论是按类型还是通过提供检查它们的Lambda:
policy
.handle(IOException.class)
.handleIf(e -> e instanceof IOException)
我们还可以对它们进行配置,将我们操作的特定结果视为失败,要么作为精确值,要么通过提供Lambda来为我们检查:
policy
.handleResult(null)
.handleResultIf(result -> result < 0)
默认情况下,策略始终将所有异常视为失败。如果我们添加异常处理,这将取代该行为,但添加特定结果的处理将是对策略的异常处理的补充。此外,我们所有的处理检查都是附加的-我们可以根据需要添加任意数量的检查,如果任何检查通过,策略将认为操作失败。
4.2 组合策略
一旦我们有了策略,我们就可以从中构建一个执行器。这是我们执行功能并获取结果的方法-要么是我们操作的实际结果,要么是由我们的策略修改的结果。我们可以通过将所有策略传递到Failsafe.with()来实现这一点,也可以通过使用compose()方法进行扩展:
Failsafe.with(defaultFallback, npeFallback, ioFallback)
.compose(timeout)
.compose(retry);
我们可以按任意顺序添加任意数量的策略,策略始终按照添加的顺序执行,每个策略都包装下一个策略。因此,上面的内容将是:
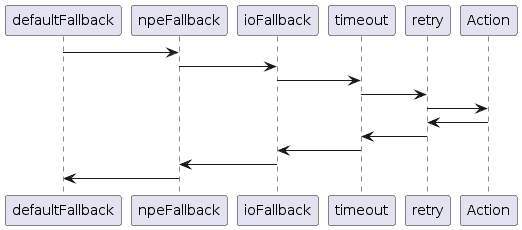
这些中的每一个都将对其包装的策略或操作的异常或返回值做出适当的反应,这使我们能够根据需要采取行动。例如,上面的代码将超时应用于所有重试,我们可以将其替换为将超时分别应用于每次尝试的重试。
4.3 执行操作
一旦制定了策略,Failsafe就会向我们返回一个FailsafeExecutor实例。然后,该实例具有一组方法,我们可以使用这些方法来执行操作,具体取决于我们想要执行的操作以及我们希望如何返回。
执行操作的最直接方法是T get<T>(CheckedSupplier<T>)和void run(CheckedRunnable)。CheckedSupplier和CheckedRunnable都是函数接口,这意味着我们可以根据需要使用Lambda或方法引用来调用这些方法。
它们之间的区别在于get()将返回操作的结果,而run()将返回void-并且操作也必须返回void:
Failsafe.with(policy).run(this::runSomething);
var result = Failsafe.with(policy).get(this::doSomething);
此外,我们还有各种方法可以异步运行我们的操作,并返回CompletableFuture作为结果。不过,这些不在本文的讨论范围内。
5. Failsafe策略
现在我们知道如何构建FailsafeExecutor来执行我们的操作,我们需要构建使用它的策略。Failsafe提供了几个标准策略,每个策略都使用构建器模式来简化构建过程。
5.1 回退策略
我们可以使用的最直接的策略是Fallback,此策略将允许我们在链式操作失败的情况下提供新的结果。
最简单的使用方法是返回一个静态值:
Fallback<Integer> policy = Fallback.builder(0).build();
在这种情况下,如果操作因任何原因失败,我们的策略将返回固定值“0”。
此外,我们可以使用CheckedRunnable或CheckedSupplier来生成替代值。根据我们的需求,这可以像在返回固定值之前写出日志消息一样简单,也可以像运行完全不同的执行路径一样复杂:
Fallback<Result> backupService = Fallback.of(this::callBackupService)
.build();
Result result = Failsafe.with(backupService)
.get(this::callPrimaryService);
在这种情况下,我们将执行callPrimaryService()。如果失败,我们将自动执行callBackupService()并尝试通过这种方式获取结果。
最后,我们可以使用Fallback.ofException()在发生任何故障时抛出特定异常。这使我们能够将任何配置的故障原因归结为单个预期异常,然后我们可以根据需要处理它:
Fallback<Result> throwOnFailure = Fallback.ofException(e -> new OperationFailedException(e));
5.2 重试策略
Fallback策略允许我们在操作失败时给出替代结果。与此相反,Retry策略允许我们简单地再次尝试原始操作。
没有任何配置,此策略将最多调用该操作3次,并在成功时返回其结果,或者如果从未成功则抛出FailsafeException:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder().build();
这已经非常有用了,因为这意味着如果我们偶尔出现错误操作,我们可以在放弃之前重试几次。
但是,我们可以进一步配置此行为。我们可以做的第一件事是使用withMaxAttempts()调用调整重试次数:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(5)
.build();
现在将执行该操作最多5次,而不是默认的3次。
我们还可以将其配置为在每次尝试之间等待固定的时间。这在短暂故障(例如网络故障)无法立即修复的情况下非常有用:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withDelay(Duration.ofMillis(250))
.build();
我们还可以使用更复杂的变体。例如,withBackoff()允许我们配置递增延迟:
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(20)
.withBackoff(Duration.ofMillis(100), Duration.ofMillis(2000))
.build();
这将在第一次故障后延迟100毫秒,在第20次故障后延迟2000毫秒,并逐渐增加中间故障的延迟。
5.3 超时策略
Fallback和Retry策略可帮助我们从操作中获得成功的结果,而Timeout策略则起到相反的作用。如果我们调用的操作花费的时间比我们预期的要长,我们可以使用它来强制失败。如果我们需要在操作花费的时间过长时失败,那么这将非常有用。
当我们构建Timeout时,我们需要提供操作失败的目标持续时间:
Timeout<Object> timeout = Timeout.builder(Duration.ofMillis(100)).build();
默认情况下,这将运行操作直至完成,如果它花费的时间比我们提供的时间长,则会失败。
或者,我们可以将其配置为在达到超时时中断操作,而不是运行至完成。当我们需要快速响应而不是因为速度太慢而失败时,这很有用:
Timeout<Object> timeout = Timeout.builder(Duration.ofMillis(100))
.withInterrupt()
.build();
我们也可以有效地将Timeout策略与Retry策略组合在一起,如果我们在重试之外组合超时,则超时期限将分布在所有重试中:
Timeout<Object> timeoutPolicy = Timeout.builder(Duration.ofSeconds(10))
.withInterrupt()
.build();
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(20)
.withBackoff(Duration.ofMillis(100), Duration.ofMillis(2000))
.build();
Failsafe.with(timeoutPolicy, retryPolicy).get(this::perform);
这将重试我们的操作最多20次,每次重试之间的延迟会增加,但如果整个重试执行时间超过10秒,则会放弃。
相反,我们可以在重试中设置超时,以便每次重试都会配置一个超时:
Timeout<Object> timeoutPolicy = Timeout.builder(Duration.ofMillis(500))
.withInterrupt()
.build();
RetryPolicy<Object> retryPolicy = RetryPolicy.builder()
.withMaxAttempts(5)
.build();
Failsafe.with(retryPolicy, timeoutPolicy).get(this::perform);
这将尝试该操作五次,并且如果每次尝试耗时超过 500 毫秒,则每次尝试都将被取消。
5.4 隔离政策
到目前为止,我们看到的所有策略都是关于控制应用程序如何应对故障的。但是,我们也可以使用一些策略来首先降低发生故障的可能性。
Bulkhead策略用于限制执行某项操作的并发次数,这可以减少外部服务的负载,从而有助于降低它们发生故障的可能性。
当我们构造Bulkhead时,我们需要配置它支持的最大并发执行数:
Bulkhead<Object> bulkhead = Bulkhead.builder(10).build();
默认情况下,当隔板已达到容量上限时,任何操作都会立即失败。
我们还可以配置隔板以在新操作进入时等待,如果容量开放,那么它将执行等待任务:
Bulkhead<Object> bulkhead = Bulkhead.builder(10)
.withMaxWaitTime(Duration.ofMillis(1000))
.build();
一旦容量可用,任务将按执行顺序通过隔板,任何等待时间超过此配置等待时间的任务都将在等待时间到期后失败。但是,它们后面的其他任务可能会成功执行。
5.5 速率限制策略
与隔板类似,速率限制器有助于限制可能发生的操作的执行次数。然而,与仅跟踪当前正在执行的操作数量的隔板不同,速率限制器会限制给定时间段内的操作数量。
Failsafe为我们提供了两种可用的速率限制器-突发和平滑。
突发速率限制器在固定的时间窗口内工作,并允许在此窗口内进行最大次数的执行:
RateLimiter<Object> rateLimiter = RateLimiter.burstyBuilder(100, Duration.ofSeconds(1))
.withMaxWaitTime(Duration.ofMillis(200))
.build();
在这种情况下,我们每秒可以执行100个操作。我们配置了一个等待时间,操作可以阻塞,直到它们被执行或失败。这些被称为突发,因为计数在窗口结束时降回0,所以我们可以突然允许执行重新开始。
特别是,有了我们的等待时间,所有阻止该等待时间的执行将突然能够在速率限制器窗口结束时执行。
平滑速率限制器的工作原理是将执行分散到时间窗口内:
RateLimiter<Object> rateLimiter = RateLimiter.smoothBuilder(100, Duration.ofSeconds(1))
.withMaxWaitTime(Duration.ofMillis(200))
.build();
这看起来与之前非常相似。但是,在这种情况下,执行将在窗口内平滑进行。这意味着我们不是允许在一秒钟的窗口内执行100次,而是每1/100秒允许一次执行。任何比这更快的执行都会达到我们的等待时间,否则会失败。
5.6 熔断策略
与大多数其他策略不同,我们可以使用断路器,这样如果操作被认为已经失败,我们的应用程序就可以快速失败。例如,如果我们正在调用远程服务并且知道它没有响应,那么重试就没有意义了-我们可以立即失败,而无需先花费时间和资源。
断路器采用三态系统工作,默认状态为“关闭”,这意味着所有操作都像断路器不存在一样重试。但是,如果这些操作中有足够多的操作失败,断路器将转为“打开”。
打开状态意味着不会重试任何操作,所有调用将立即失败。断路器将保持这种状态一段时间,然后才转为半开状态。
半开状态意味着重试执行操作,但我们有不同的失败阈值来确定是否转向关闭或打开。
例如:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureThreshold(7, 10)
.withDelay(Duration.ofMillis(500))
.withSuccessThreshold(4, 5)
.build();
如果在最近的10个请求中有7次失败,则此设置将从“关闭”变为“打开”;500毫秒后,从“打开”变为“半开”;如果在最近的10个请求中有4次成功,则从“半开”变为“关闭”;如果在最近的5个请求中有2次失败,则返回“打开”。
我们还可以将故障阈值配置为基于时间的。例如,如果在过去30秒内发生5次故障,我们将断开电路:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureThreshold(5, Duration.ofSeconds(30))
.build();
我们可以将其配置为请求的百分比,而不是固定数字。例如,如果在任何5分钟内有至少100个请求,故障率为20%,则打开电路:
CircuitBreaker<Object> circuitBreaker = CircuitBreaker.builder()
.withFailureRateThreshold(20, 100, Duration.ofMinutes(5))
.build();
这样做可以让我们更快地调整负载。如果负载很低,我们可能根本不想检查故障,但如果负载很高,故障的可能性就会增加,因此我们希望只有当负载超过阈值时才做出反应。
6. 总结
在本文中,我们广泛介绍了Failsafe。
Post Directory
