1. 简介
在本文中,我们将使用deeplearning4j(dl4j)库(一种现代且强大的机器学习工具)创建一个简单的神经网络。
在我们开始之前,本指南要求读者具有线性代数、统计学、机器学习理论以及一名经验丰富的ML工程师所必需的许多其他主题的深厚知识。
2. 什么是深度学习?
神经网络是由相互连接的节点层组成的计算模型。
节点是类似于神经元的数字数据处理器,它们从输入中获取数据,对这些数据应用一些权重和函数,并将结果发送到输出。这种网络可以用一些源数据示例进行训练。
训练本质上是在节点中保存一些数值状态(权重),这些状态稍后会影响计算。训练示例可能包含具有特征的数据项以及这些项的某些已知类别(例如,“这组16 × 16像素包含一个手写字母“a””)。
训练完成后,神经网络可以从新数据中获取信息,即使它以前没有见过这些特定的数据项。一个模型良好、训练有素的网络可以识别图像、手写字母和语音,处理统计数据以产生商业智能结果等等。
近年来,随着高性能和并行计算的发展,深度神经网络成为可能。这种网络与简单的神经网络不同,它们由多个中间层(或隐藏层)组成。这种结构允许网络以更复杂的方式(以递归、循环、卷积方式等)处理数据,并从中提取更多信息。
3. 设置项目
要使用该库,我们至少需要Java 7。此外,由于一些原生组件,它仅适用于64位JVM版本。
在开始指南之前,让我们检查是否满足要求:
$ java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
首先,让我们将所需的库添加到Maven pom.xml文件中,我们将库的版本提取到properties条目中(有关库的最新版本,请查看Maven Central仓库):
<properties>
<dl4j.version>0.9.1</dl4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>${dl4j.version}</version>
</dependency>
</dependencies>
请注意,nd4j-native-platform依赖是几种可用的实现之一。
它依赖于适用于许多不同平台(macOS、Windows、Linux、Android等)的原生库,如果我们想在支持CUDA编程模型的显卡上执行计算,我们还可以将后端切换到nd4j-cuda-8.0-platform。
4. 准备数据
4.1 准备数据集文件
我们将编写机器学习的“Hello World”-鸢尾花数据集的分类,这是从不同物种的花朵(山鸢尾、杂色鸢尾和维吉尼亚鸢尾)中收集的一组数据。
这些物种的花瓣和萼片的长度和宽度各不相同,编写一个精确的算法来对输入数据项进行分类(即确定特定花朵属于哪个物种)会很困难,但训练有素的神经网络可以快速且几乎不会出错地对其进行分类。
我们将使用该数据的CSV版本,其中第0..3列包含物种的不同特征,第4列包含记录的类别或物种,用值0、1或2编码:
5.1,3.5,1.4,0.2,0
4.9,3.0,1.4,0.2,0
4.7,3.2,1.3,0.2,0
...
7.0,3.2,4.7,1.4,1
6.4,3.2,4.5,1.5,1
6.9,3.1,4.9,1.5,1
...
4.2 向量化并读取数据
我们用数字对类进行编码,因为神经网络使用数字。将现实世界的数据项转换为一系列数字(向量)称为向量化-deeplearning4j使用datavec库来执行此操作。
首先,让我们使用此库输入包含向量化数据的文件。创建CSVRecordReader时,我们可以指定要跳过的行数(例如,如果文件有标头行)和分隔符(在我们的例子中是逗号):
try (RecordReader recordReader = new CSVRecordReader(0, ',')) {
recordReader.initialize(new FileSplit(new ClassPathResource("iris.txt").getFile()));
// ...
}
要迭代记录,我们可以使用DataSetIterator接口的多种实现中的任何一种。数据集可能非常庞大,分页或缓存值的能力可能会派上用场。
但是我们的小数据集仅包含150条记录,因此让我们通过调用iterator.next()一次将所有数据读入内存。
我们还指定了类列的索引,在我们的例子中,它与特征计数(4)和类的总数(3)相同。
另请注意,我们需要对数据集进行混洗,以摆脱原始文件中的类排序。
我们指定一个常量随机种子(42),而不是默认的System.currentTimeMillis()调用,这样改组的结果将始终相同。这样,我们每次运行程序时都能获得稳定的结果:
DataSetIterator iterator = new RecordReaderDataSetIterator(recordReader, 150, FEATURES_COUNT, CLASSES_COUNT);
DataSet allData = iterator.next();
allData.shuffle(42);
4.3 规范化和拆分
在训练之前,我们应该对数据进行另一件事,即对其进行标准化。标准化分为两个阶段:
- 收集一些关于数据的统计数据(拟合)
- 以某种方式改变(转换)数据以使其统一
对于不同类型的数据,规范化可能有所不同。
例如,如果我们要处理各种尺寸的图像,我们应该首先收集尺寸统计数据,然后将图像缩放到统一的尺寸。
但对于数字来说,规范化通常意味着将它们转换为所谓的正态分布。NormalizerStandardize类可以帮助我们实现这一点:
DataNormalization normalizer = new NormalizerStandardize();
normalizer.fit(allData);
normalizer.transform(allData);
现在数据已经准备好了,我们需要将集合分成两部分。
第一部分将用于训练,我们将使用数据的第二部分(网络根本看不到)来测试训练好的网络。
这将使我们能够验证分类是否正确,我们将取65%的数据(0.65)用于训练,其余35%用于测试:
SplitTestAndTrain testAndTrain = allData.splitTestAndTrain(0.65);
DataSet trainingData = testAndTrain.getTrain();
DataSet testData = testAndTrain.getTest();
5. 准备网络配置
5.1 流式的配置生成器
现在我们可以使用流畅的构建器来构建我们的网络配置:
MultiLayerConfiguration configuration
= new NeuralNetConfiguration.Builder()
.iterations(1000)
.activation(Activation.TANH)
.weightInit(WeightInit.XAVIER)
.learningRate(0.1)
.regularization(true).l2(0.0001)
.list()
.layer(0, new DenseLayer.Builder().nIn(FEATURES_COUNT).nOut(3).build())
.layer(1, new DenseLayer.Builder().nIn(3).nOut(3).build())
.layer(2, new OutputLayer.Builder(
LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.activation(Activation.SOFTMAX)
.nIn(3).nOut(CLASSES_COUNT).build())
.backprop(true).pretrain(false)
.build();
即使采用这种简化的流式方式构建网络模型,仍有很多内容需要消化,还有很多参数需要调整。让我们分解一下这个模型。
5.2 设置网络参数
iterations()构建器方法指定优化迭代的次数。
迭代优化意味着对训练集进行多次传递,直到网络收敛到一个良好的结果。
通常,在对真实大型数据集进行训练时,我们会使用多个epoch(数据通过网络的完整传递),并且每个epoch进行一次迭代。但由于我们的初始数据集很小,因此我们将使用一个epoch和多个迭代。
activation()是一个在节点内部运行的函数,用于确定其输出。
最简单的激活函数是线性f(x)= x,但事实证明,只有非线性函数才能让网络使用少量节点解决复杂任务。
有许多不同的激活函数可用,我们可以在org.nd4j.linalg.activations.Activation枚举中查找。如果需要,我们也可以编写自己的激活函数。但我们将使用提供的双曲正切(tanh)函数。
weightInit()方法指定了设置网络初始权重的众多方法之一,正确的初始权重可以极大地影响训练结果。我们不必过多考虑数学问题,先将其设置为高斯分布的形式(WeightInit.XAVIER),因为这通常是开始的好选择。
所有其他权重初始化方法都可以在org.deeplearning4j.nn.weights.WeightInit枚举中查找。
学习率是影响网络学习能力的关键参数。
在更复杂的情况下,我们可能会花费大量时间来调整此参数。但对于我们的简单任务,我们将使用一个相当重要的值0.1,并使用learningRate()构建器方法进行设置。
训练神经网络的一个问题是,当网络“记忆”训练数据时出现过度拟合的情况。
当网络为训练数据设置过高的权重并对任何其他数据产生不良结果时,就会发生这种情况。
为了解决这个问题,我们将使用.regularization(true).l2(0.0001)行设置l2正则化,正则化会“惩罚”权重过大的网络并防止过度拟合。
5.3 构建网络层
接下来,我们创建一个密集(也称为完全连接)层的网络。
第一层应包含与训练数据中的列相同数量的节点(4)。
第二个密集层将包含三个节点,这是我们可以改变的值,但前一层的输出数量必须相同。
最后的输出层应该包含与类数匹配的节点数(3),网络结构如图所示:
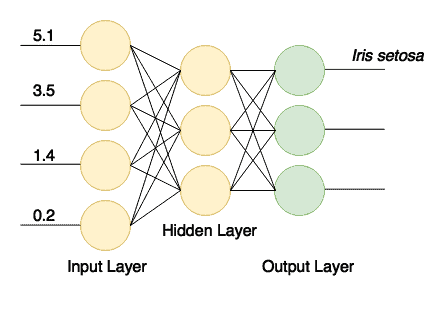
训练成功后,我们将拥有一个网络,它通过输入接收四个值,并向其三个输出之一发送信号。这是一个简单的分类器。
最后,为了完成网络构建,我们设置了反向传播(最有效的训练方法之一)并使用.backprop(true).pretrain(false)行禁用预训练。
6. 创建和训练网络
现在让我们从配置中创建一个神经网络,初始化并运行它:
MultiLayerNetwork model = new MultiLayerNetwork(configuration);
model.init();
model.fit(trainingData);
现在我们可以使用数据集的其余部分测试训练后的模型,并使用三个类别的评估指标验证结果:
INDArray output = model.output(testData.getFeatureMatrix());
Evaluation eval = new Evaluation(3);
eval.eval(testData.getLabels(), output);
如果我们现在打印出eval.stats(),我们会看到我们的网络在对鸢尾花进行分类方面相当不错,尽管它确实三次将第1类误认为第2类。
Examples labeled as 0 classified by model as 0: 19 times
Examples labeled as 1 classified by model as 1: 16 times
Examples labeled as 1 classified by model as 2: 3 times
Examples labeled as 2 classified by model as 2: 15 times
==========================Scores========================================
# of classes: 3
Accuracy: 0.9434
Precision: 0.9444
Recall: 0.9474
F1 Score: 0.9411
Precision, recall & F1: macro-averaged (equally weighted avg. of 3 classes)
========================================================================
流式的配置构建器允许我们快速添加或修改网络层,或者调整其他参数以查看我们的模型是否可以改进。
7. 总结
在本文中,我们使用deeplearning4j库构建了一个简单但功能强大的神经网络。
Post Directory
