1. 简介
逻辑回归是机器学习(ML)从业者工具箱中的一个重要工具。
在本教程中,我们将探讨逻辑回归背后的主要思想。
首先,让我们简单概述一下ML范式和算法。
2. 概述
机器学习使我们能够解决能够以人性化术语表述的问题。然而,这一事实可能对我们软件开发人员来说是一个挑战,我们已经习惯于解决能够以计算机友好术语表述的问题。例如,作为人类,我们可以轻松地检测照片上的物体或确定短语的情绪。我们如何为计算机表述这样的问题?
为了找到解决方案,机器学习中有一个称为训练的特殊阶段。在此阶段,我们将输入数据提供给算法,以便算法尝试得出一组最佳参数(即所谓的权重)。我们提供给算法的输入数据越多,我们期望算法的预测就越精确。
训练是迭代ML工作流程的一部分:

我们从获取数据开始。通常,数据来自不同的来源。因此,我们必须使其具有相同的格式。我们还应该控制数据集公平地代表研究领域,如果模型从未在红苹果上进行过训练,它很难预测它。
接下来,我们应该构建一个能够使用数据并进行预测的模型。在机器学习中,没有适用于所有情况的预定义模型。
在寻找正确的模型时,我们很容易建立一个模型,对其进行训练,看到它的预测后就丢弃它,因为我们对它做出的预测不满意。在这种情况下,我们应该退一步,再建立另一个模型,然后重复这个过程。
3. 机器学习范式
在机器学习中,根据我们掌握的输入数据类型,我们可以挑选出三个主要范例:
- 监督学习(图像分类、对象识别、情绪分析)
- 无监督学习(异常检测)
- 强化学习(游戏策略)
我们将在本教程中描述的情况属于监督学习。
4. 机器学习工具箱
在ML中,我们可以在构建模型时应用一组工具。让我们来介绍一下其中的一些:
在构建具有高预测能力的模型时,我们可能会结合使用多种工具。事实上,在本教程中,我们的模型将使用逻辑回归和神经网络。
5. 机器学习库
尽管Java不是用于原型化ML模型的最流行语言,但它在包括ML在内的许多领域都享有创建强大软件的可靠工具的美誉。因此,我们可能会找到用Java编写的ML库。
在此背景下,我们可以提到事实上的标准库Tensorflow,它也有Java版本。另一个值得一提的是名为Deeplearning4j的深度学习库,这是一个非常强大的工具,我们也将在本教程中使用它。
6. 逻辑回归在数字识别中的应用
逻辑回归的主要思想是建立一个模型,尽可能准确地预测输入数据的标签。
我们训练模型,直到所谓的损失函数或目标函数达到某个最小值。损失函数取决于实际模型预测和预期预测(输入数据的标签),我们的目标是尽量减少实际模型预测和预期预测之间的差异。
如果我们对这个最小值不满意,我们应该建立另一个模型并再次进行训练。
为了了解逻辑回归的实际作用,我们以手写数字识别为例进行说明。这个问题已经成为一个经典问题,Deeplearning4j库有一系列实际示例,展示了如何使用其API。本教程的代码相关部分主要基于MNIST分类器。
6.1 输入数据
作为输入数据,我们使用著名的MNIST手写数字数据库。作为输入数据,我们有28 × 28像素的灰度图像。每幅图像都有一个自然标签,即图像所代表的数字:

为了评估我们要构建的模型的效率,我们将输入数据分为训练集和测试集:
DataSetIterator train = new RecordReaderDataSetIterator(...);
DataSetIterator test = new RecordReaderDataSetIterator(...);
一旦我们对输入图像进行标记并将其分成两组,“数据阐述”阶段就结束了,我们就可以进入“模型构建”阶段。
6.2 模型构建
正如我们提到的,没有一种模型可以在所有情况下都表现良好。然而,经过多年的机器学习研究,科学家们已经找到了在识别手写数字方面表现非常出色的模型。在这里,我们使用所谓的LeNet-5模型。
LeNet-5是一个神经网络,由一系列层组成,将28 × 28像素图像转换为十维向量:

十维输出向量包含输入图像的标签为0、1、2等的概率。
例如,如果输出向量具有以下形式:
{0.1, 0.0, 0.3, 0.2, 0.1, 0.1, 0.0, 0.1, 0.1, 0.0}
这意味着输入图像为零的概率为0.1,为一的概率为0,为二的概率为0.3,等等。我们看到最大概率(0.3)对应于标签3。
让我们深入研究模型构建的细节,我们省略Java特定的细节,专注于ML概念。
我们通过创建MultiLayerNetwork对象来建立模型:
MultiLayerNetwork model = new MultiLayerNetwork(config);
在其构造函数中,我们应该传递一个MultiLayerConfiguration对象,这是描述神经网络几何形状的对象。为了定义网络几何形状,我们应该定义每一层。
让我们展示如何使用第一个和第二个来实现这一点:
ConvolutionLayer layer1 = new ConvolutionLayer
.Builder(5, 5).nIn(channels)
.stride(1, 1)
.nOut(20)
.activation(Activation.IDENTITY)
.build();
SubsamplingLayer layer2 = new SubsamplingLayer
.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build();
我们看到,层的定义包含大量临时参数,这些参数对整个网络性能有重大影响,这正是我们在众多模型中找到一个好模型的能力变得至关重要的地方。
现在,我们准备构建MultiLayerConfiguration对象:
MultiLayerConfiguration config = new NeuralNetConfiguration.Builder()
// preparation steps
.list()
.layer(0, layer1)
.layer(1, layer2)
// other layers and final steps
.build();
我们将其传递给MultiLayerNetwork构造函数。
6.3 训练
我们构建的模型包含431080个参数或权重,我们不会在这里给出这个数字的精确计算,但我们应该知道,仅第一层就有超过24 x 24 x 20 = 11520个权重。
训练阶段非常简单:
model.fit(train);
最初,这431080个参数具有一些随机值,但经过训练后,它们会获得一些决定模型性能的值。我们可以评估模型的预测能力:
Evaluation eval = model.evaluate(test);
logger.info(eval.stats());
LeNet-5模型即使只进行一次训练迭代(epoch)也能达到近99%的相当高的准确率。如果我们想要获得更高的准确率,我们应该使用简单的for循环进行更多次迭代:
for (int i = 0; i < epochs; i++) {
model.fit(train);
train.reset();
test.reset();
}
6.4 预测
现在,当我们训练模型并且对其在测试数据上的预测感到满意时,我们可以尝试使用一些全新的输入来测试该模型。为此,让我们创建一个新的类MnistPrediction,我们将从文件系统中选择的文件中加载图像:
INDArray image = new NativeImageLoader(height, width, channels).asMatrix(file);
new ImagePreProcessingScaler(0, 1).transform(image);
变量image包含缩小为28 × 28灰度的图像,我们可以将其输入到我们的模型中:
INDArray output = model.output(image);
变量输出将包含图像为0、1、2等的概率。
现在我们来玩一下,写一个数字2,将这个图像数字化,并将其输入到模型中。我们可能会得到这样的结果:
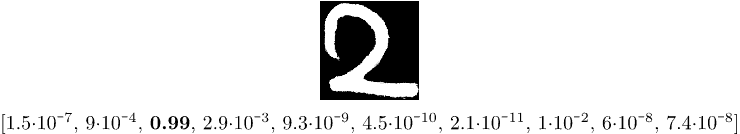
如我们所见,最大值为0.99的组件的索引为2,这意味着模型已正确识别我们的手写数字。
7. 总结
在本教程中,我们描述了机器学习的一般概念,我们在应用于手写数字识别的逻辑回归示例中说明了这些概念。
Post Directory
