1. 概述
本文介绍了LMAX Disruptor,并讨论了它如何帮助实现低延迟的软件并发。我们还将看到Disruptor库的基本用法。
2. 什么是Disruptor?
Disruptor是LMAX编写的开源Java库,它是一个用于处理大量事务的并发编程框架,具有低延迟(并且没有并发代码的复杂性)。性能优化是通过利用底层硬件效率的软件设计来实现的。
2.1 机械同情
让我们从机械同情的核心概念开始-那就是了解底层硬件如何运行,并以最适合该硬件的方式进行编程。
例如,让我们看看CPU和内存组织如何影响软件性能。CPU和主内存之间有几层缓存,当CPU执行操作时,它首先在L1中查找数据,然后是L2,然后是L3,最后是主内存。距离越远,操作所需的时间就越长。
如果对一段数据执行相同的操作多次(例如,循环计数器),则将该数据加载到非常靠近CPU的地方是有意义的。
一些关于缓存未命中成本的指示性数字:
| 从CPU到 | CPU周期 | 时间 |
|---|---|---|
| 主存储器 | 非常多 | ~60-80纳秒 |
| L3缓存 | ~40-45 个周期 | ~15纳秒 |
| L2缓存 | ~10个周期 | ~3纳秒 |
| L1缓存 | ~3-4个周期 | ~1纳秒 |
| 寄存器 | 1个周期 | 非常非常快 |
2.2 为什么不使用队列
队列实现往往存在对头部、尾部和大小变量的写入争用。由于消费者和生产者的速度不同,队列通常总是接近满或接近空,它们很少在生产率和消费率均衡的平衡中间地带运行。
为了解决写入争用问题,队列经常使用锁,这会导致上下文切换到内核。发生这种情况时,所涉及的处理器可能会丢失其缓存中的数据。
为了获得最佳的缓存行为,设计中应该只有一个核心写入任何内存位置(多个读取器也可以,因为处理器通常在其缓存之间使用特殊的高速链接)。队列不符合单写入器原则。
如果两个独立的线程写入两个不同的值,则每个核心都会使另一个核心的缓存行无效(数据以固定大小的块(称为缓存行)在主内存和缓存之间传输)。这是两个线程之间的写入争用,即使它们写入的是两个不同的变量。这称为伪共享,因为每次访问头部时,尾部也会被访问,反之亦然。
2.3 Disruptor的工作原理
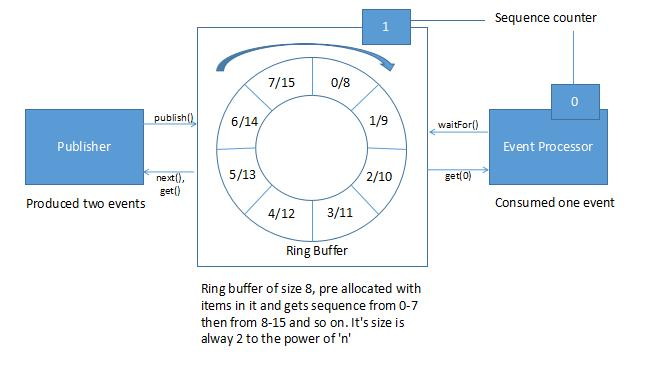
Disruptor有一个基于数组的循环数据结构(环形缓冲区),它是一个具有指向下一个可用插槽的指针的数组。它填充了预先分配的传输对象,生产者和消费者可以在没有锁定或争用的情况下将数据写入和读取到环形缓冲区中。
在Disruptor中,所有事件都会发布给所有消费者(多播),通过单独的下游队列进行并行消费。由于消费者并行处理,因此需要协调消费者之间的依赖关系(依赖图)。
生产者和消费者有一个序列计数器,用于指示其当前正在缓冲区中的哪个插槽上工作。每个生产者/消费者都可以写入自己的序列计数器,但可以读取其他的序列计数器。生产者和消费者读取计数器以确保其想要写入的插槽可用且无需任何锁定。
3. 使用Disruptor库
3.1 Maven依赖
让我们首先在pom.xml中添加Disruptor库依赖:
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.3.6</version>
</dependency>
你可以在此处查看依赖的最新版本。
3.2 定义事件
让我们定义携带数据的事件:
public static class ValueEvent {
private int value;
public final static EventFactory EVENT_FACTORY = () -> new ValueEvent();
// standard getters and setters
}
EventFactory允许Disruptor预先分配事件。
3.3 消费者
消费者从环形缓冲区读取数据,让我们定义一个处理事件的消费者:
public class SingleEventPrintConsumer {
// ...
public EventHandler<ValueEvent>[] getEventHandler() {
EventHandler<ValueEvent> eventHandler
= (event, sequence, endOfBatch)
-> print(event.getValue(), sequence);
return new EventHandler[] { eventHandler };
}
private void print(int id, long sequenceId) {
logger.info("Id is " + id
+ " sequence id that was used is " + sequenceId);
}
}
在我们的示例中,消费者只是打印日志。
3.4 构建Disruptor
构建Disruptor:
ThreadFactory threadFactory = DaemonThreadFactory.INSTANCE;
WaitStrategy waitStrategy = new BusySpinWaitStrategy();
Disruptor<ValueEvent> disruptor = new Disruptor<>(
ValueEvent.EVENT_FACTORY,
16,
threadFactory,
ProducerType.SINGLE,
waitStrategy);
在Disruptor的构造函数中,定义以下内容:
- 事件工厂:负责生成在初始化期间存储在环形缓冲区中的对象
- 环形缓冲区的大小:我们将环形缓冲区的大小定义为16,它必须是2的幂,否则初始化时会抛出异常。这很重要,因为使用逻辑二进制运算符(例如mod运算)可以轻松执行大多数运算
- 线程工厂:为事件处理器创建线程的工厂
- 生产者类型:指定我们是否有单个或多个生产者
- 等待策略:定义我们如何处理跟不上生产者速度的慢速消费者
连接消费者处理程序:
disruptor.handleEventsWith(getEventHandler());
可以使用Disruptor为多个消费者提供处理生产者生成的数据的功能,在上面的例子中,我们只有一个消费者,也就是事件处理程序。
3.5 启动Disruptor
要启动Disruptor:
RingBuffer<ValueEvent> ringBuffer = disruptor.start();
3.6 生成和发布事件
生产者按顺序将数据放入环形缓冲区,生产者必须知道下一个可用插槽,这样他们就不会覆盖尚未使用的数据。
使用Disruptor的RingBuffer进行发布:
for (int eventCount = 0; eventCount < 32; eventCount++) {
long sequenceId = ringBuffer.next();
ValueEvent valueEvent = ringBuffer.get(sequenceId);
valueEvent.setValue(eventCount);
ringBuffer.publish(sequenceId);
}
在这里,生产者按顺序生产和发布元素。这里需要注意的是,Disruptor的工作方式类似于两阶段提交协议。它读取一个新的序列ID并发布,下一次它应该获取序列ID + 1作为下一个序列ID。
4. 总结
在本教程中,我们了解了Disruptor是什么以及它如何实现低延迟的并发,我们了解了机械同情的概念以及如何利用它来实现低延迟。然后,我们查看了一个使用Disruptor库的示例。
Post Directory
