1. 概述
TensorFlow是一个用于数据流编程的开源库,它最初由Google开发,可用于多种平台。尽管TensorFlow可以在单个核心上运行,但它也可以轻松地从多个CPU、GPU或TPU中受益。
在本教程中,我们将介绍TensorFlow的基础知识以及如何在Java中使用它。请注意,TensorFlow Java API是一个实验性API,因此不受任何稳定性保证的保护。我们将在本教程的后面介绍使用TensorFlow Java API的可能用例。
2. 基础知识
TensorFlow计算基本上围绕两个基本概念:Graph和Session。让我们快速浏览一下它们,以获得完成本教程其余部分所需的背景知识。
2.1 TensorFlow图
首先,让我们了解TensorFlow程序的基本构建块。计算在TensorFlow中表示为图,图通常是操作和数据的有向无环图,例如:
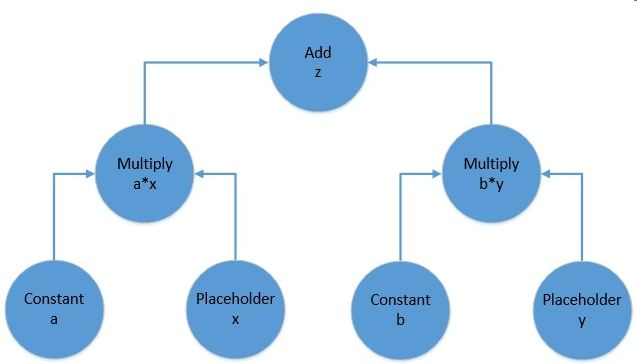
上图表示以下方程的计算图:
f(x, y) = z = a*x + b*y
TensorFlow计算图由两个元素组成:
- 张量:这是TensorFlow中数据的核心单元,它们表示为计算图中的边,描绘了数据在图中流动的轨迹。张量的形状可以是任意数量的维度,张量的维度数通常称为其阶数。因此,标量是阶数为0的张量,向量是阶数为1的张量,矩阵是阶数为2的张量,依此类推。
- 操作:这些是计算图中的节点,它们指的是在输入到操作中的张量上可能发生的各种计算,它们通常也会产生来自计算图中操作的张量。
2.2 TensorFlow会话
现在,TensorFlow图只是计算的示意图,实际上不包含任何值。这样的图必须在所谓的TensorFlow会话中运行,才能对图中的张量进行评估。会话可以从图中获取一组要评估的张量作为输入参数,然后它在图中向后运行并运行评估这些张量所需的所有节点。
有了这些知识,我们现在就可以将其应用到Java API中了。
3. Maven设置
我们将建立一个快速Maven项目,以在Java中创建和运行TensorFlow图。我们只需要tensorflow依赖:
<dependency>
<groupId>org.tensorflow</groupId>
<artifactId>tensorflow</artifactId>
<version>1.12.0</version>
</dependency>
4. 创建图
现在让我们尝试使用TensorFlow Java API构建上一节中讨论的图。更准确地说,在本教程中,我们将使用TensorFlow Java API来求解以下方程表示的函数:
z = 3*x + 2*y
第一步是声明并初始化一个图:
Graph graph = new Graph()
现在,我们必须定义所需的所有操作。请记住,TensorFlow中的操作会消耗并产生0个或多个张量。此外,图中的每个节点都是一个操作,包括常量和占位符。这似乎违反直觉,但请忍耐一下。
Graph类有一个名为opBuilder()的通用函数,用于在TensorFlow上构建任何类型的操作。
4.1 定义常量
首先,让我们在上面的图中定义常量操作。请注意,常量操作需要一个张量作为其值:
Operation a = graph.opBuilder("Const", "a")
.setAttr("dtype", DataType.fromClass(Double.class))
.setAttr("value", Tensor.<Double>create(3.0, Double.class))
.build();
Operation b = graph.opBuilder("Const", "b")
.setAttr("dtype", DataType.fromClass(Double.class))
.setAttr("value", Tensor.<Double>create(2.0, Double.class))
.build();
这里,我们定义了一个常量类型的Operation,将Double值2.0和3.0输入到Tensor中。乍一看,这似乎有点难以理解,但目前Java API就是这样的。在Python等语言中,这些构造要简洁得多。
4.2 定义占位符
虽然我们需要为常量提供值,但占位符在定义时不需要值。当图在会话内运行时,需要为占位符提供值。我们将在本教程的后面部分介绍该部分。
现在,让我们看看如何定义占位符:
Operation x = graph.opBuilder("Placeholder", "x")
.setAttr("dtype", DataType.fromClass(Double.class))
.build();
Operation y = graph.opBuilder("Placeholder", "y")
.setAttr("dtype", DataType.fromClass(Double.class))
.build();
请注意,我们不必为占位符提供任何值。运行时,这些值将作为张量输入。
4.3 定义函数
最后,我们需要定义方程的数学运算,即乘法和加法来得到结果。
这些只不过是TensorFlow中的操作,并且Graph.opBuilder()再次派上用场:
Operation ax = graph.opBuilder("Mul", "ax")
.addInput(a.output(0))
.addInput(x.output(0))
.build();
Operation by = graph.opBuilder("Mul", "by")
.addInput(b.output(0))
.addInput(y.output(0))
.build();
Operation z = graph.opBuilder("Add", "z")
.addInput(ax.output(0))
.addInput(by.output(0))
.build();
在这里,我们定义了Operation,两个用于将输入相乘,最后一个用于将中间结果相加。请注意,这里的操作接收的张量只是我们之前操作的输出。
请注意,我们使用索引“0”从Operation中获取输出Tensor。如前所述,Operation可以产生一个或多个Tensor,因此在检索它的句柄时,我们需要提及索引。因为我们知道我们的操作只返回一个Tensor,所以“0”就可以了。
5. 可视化图
随着图规模的扩大,很难对其进行跟踪。因此,以某种方式对其进行可视化就显得非常重要。我们总是可以像之前创建的小图一样手绘,但对于较大的图来说,这并不实用。TensorFlow提供了一个名为TensorBoard的实用程序来实现这一点。
不幸的是,Java API没有能力生成TensorBoard使用的事件文件。但使用Python中的API,我们可以生成如下事件文件:
writer = tf.summary.FileWriter('.')
......
writer.add_graph(tf.get_default_graph())
writer.flush()
如果这在Java上下文中没有意义,请不要担心,这只是为了完整性而在这里添加的,并不是继续本教程其余部分所必需的。
我们现在可以在TensorBoard中加载和可视化事件文件,如下所示:
tensorboard --logdir .
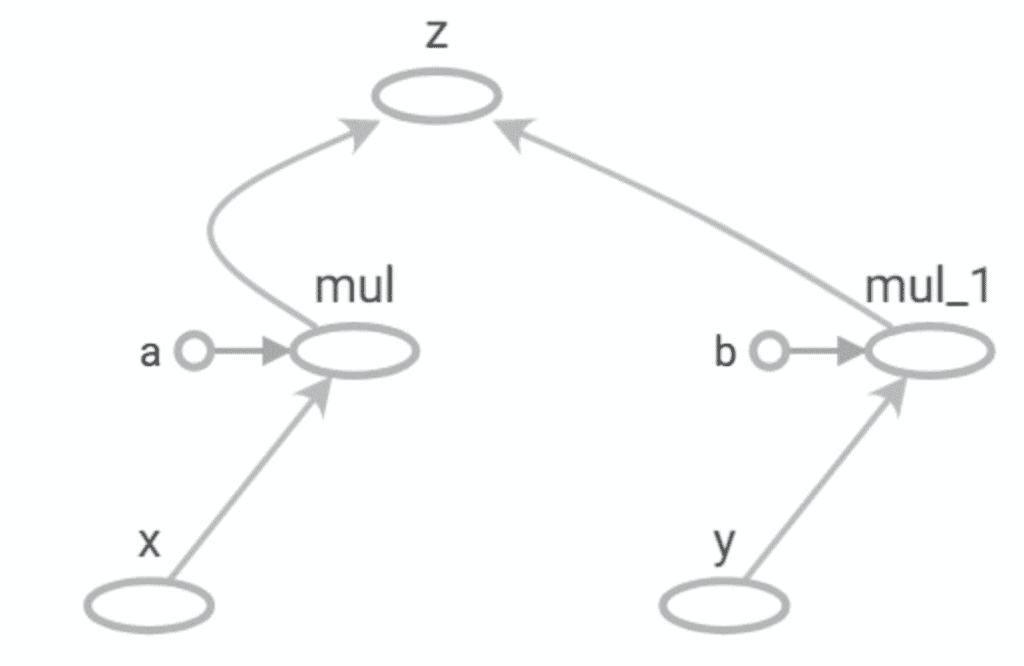
TensorBoard是TensorFlow安装的一部分。
请注意这与之前手动绘制的图的相似性。
6. 使用会话
现在,我们已经在TensorFlow Java API中为我们的简单方程创建了一个计算图。但我们如何运行它呢?在解决这个问题之前,让我们看看我们刚刚创建的图的状态如何。如果我们尝试打印最终Operation “z”的输出:
System.out.println(z.output(0));
这将导致类似这样的结果:
<Add 'z:0' shape=<unknown> dtype=DOUBLE>
这不是我们所期望的,但如果我们回想一下我们之前讨论的内容,这实际上是有道理的。我们刚刚定义的Graph尚未运行,因此其中的张量实际上不包含任何实际值。上面的输出只是说这将是Double类型的张量。
现在让我们定义一个会话来运行我们的图:
Session sess = new Session(graph)
最后,我们现在准备运行我们的图并得到我们期望的输出:
Tensor<Double> tensor = sess.runner().fetch("z")
.feed("x", Tensor.<Double>create(3.0, Double.class))
.feed("y", Tensor.<Double>create(6.0, Double.class))
.run().get(0).expect(Double.class);
System.out.println(tensor.doubleValue());
那么我们在这里做什么?这应该相当直观:
- 从Session中获取Runner
- 通过名称“z”定义要获取的Operation
- 输入占位符“x”和“y”的张量
- 在Session中运行Graph
现在我们看到标量输出:
21.0
这正如我们所期望的。
7. Java API的用例
就这一点而言,TensorFlow可能听起来有点儿大材小用,无法执行基本操作。但TensorFlow的设计初衷当然是运行比这大得多的图。
此外,它在实际模型中处理的张量在大小和阶数上要大得多,这些是TensorFlow真正发挥作用的实际机器学习模型。
不难看出,随着图的大小增加,使用TensorFlow中的核心API会变得非常麻烦。为此,TensorFlow提供了Keras等高级API来处理复杂模型。不幸的是,目前Java上几乎没有对Keras的官方支持。
但是,我们可以使用Python直接在TensorFlow中或使用Keras等高级API来定义和训练复杂模型。随后,我们可以导出经过训练的模型,并使用TensorFlow Java API在Java中使用该模型。
那么,我们为什么要这样做呢?这对于我们想要在运行Java的现有客户端中使用机器学习功能的情况特别有用。例如,在Android设备上为用户图像推荐标题。尽管如此,在某些情况下,我们对机器学习模型的输出感兴趣,但不一定想用Java创建和训练该模型。
这是TensorFlow Java API最常用的地方,我们将在下一节中介绍如何实现这一点。
8. 使用已保存的模型
现在我们将了解如何将TensorFlow中的模型保存到文件系统,并可能以完全不同的语言和平台将其加载回来。TensorFlow提供了API来以与语言和平台无关的结构(称为Protocol Buffer)生成模型文件。
8.1 将模型保存到文件系统
我们将首先定义之前在Python中创建的相同图,并将其保存到文件系统。
让我们看看是否可以用Python来实现这个功能:
import tensorflow as tf
graph = tf.Graph()
builder = tf.saved_model.builder.SavedModelBuilder('./model')
with graph.as_default():
a = tf.constant(2, name='a')
b = tf.constant(3, name='b')
x = tf.placeholder(tf.int32, name='x')
y = tf.placeholder(tf.int32, name='y')
z = tf.math.add(a*x, b*y, name='z')
sess = tf.Session()
sess.run(z, feed_dict = {x: 2, y: 3})
builder.add_meta_graph_and_variables(sess, [tf.saved_model.tag_constants.SERVING])
builder.save()
由于本教程的重点是Java,因此我们不必过多关注Python中此代码的细节,只需注意它生成了一个名为“saved_model.pb”的文件即可。请注意与Java相比,定义类似图的简洁性。
8.2 从文件系统加载模型
现在我们将“saved_model.pb”加载到Java中,Java TensorFlow API具有SavedModelBundle来处理已保存的模型:
SavedModelBundle model = SavedModelBundle.load("./model", "serve");
Tensor<Integer> tensor = model.session().runner().fetch("z")
.feed("x", Tensor.<Integer>create(3, Integer.class))
.feed("y", Tensor.<Integer>create(3, Integer.class))
.run().get(0).expect(Integer.class);
System.out.println(tensor.intValue());
现在应该可以直观地理解上面的代码在做什么,它只是从Protocol Buffer加载模型图并在其中提供会话。从那里开始,我们几乎可以对该图进行任何操作,就像我们对本地定义的图所做的那样。
9. 总结
总而言之,在本教程中,我们介绍了与TensorFlow计算图相关的基本概念。我们了解了如何使用TensorFlow Java API来创建和运行这样的图。然后,我们讨论了与TensorFlow相关的Java API的用例。
在此过程中,我们还了解了如何使用TensorBoard将图可视化,以及如何使用Protocol Buffer保存和重新加载模型。
Post Directory
