1. 简介
在现代软件开发中,微服务架构非常流行,跟踪和分析跨各种服务的请求流的能力至关重要。因此,分布式跟踪成为一种关键工具,可以深入了解我们系统的性能和行为。
在本教程中,我们将介绍Brave,它是Java生态系统中流行的分布式跟踪检测库。
2. 理解分布式跟踪
分布式跟踪是一种用于监控和排除由互连服务组成的复杂分布式系统故障的方法。在此类系统中,请求可能会遍历多个服务,每个服务负责执行特定任务。因此,如果不使用一些专用工具,跟踪请求的旅程可能会变得很困难。
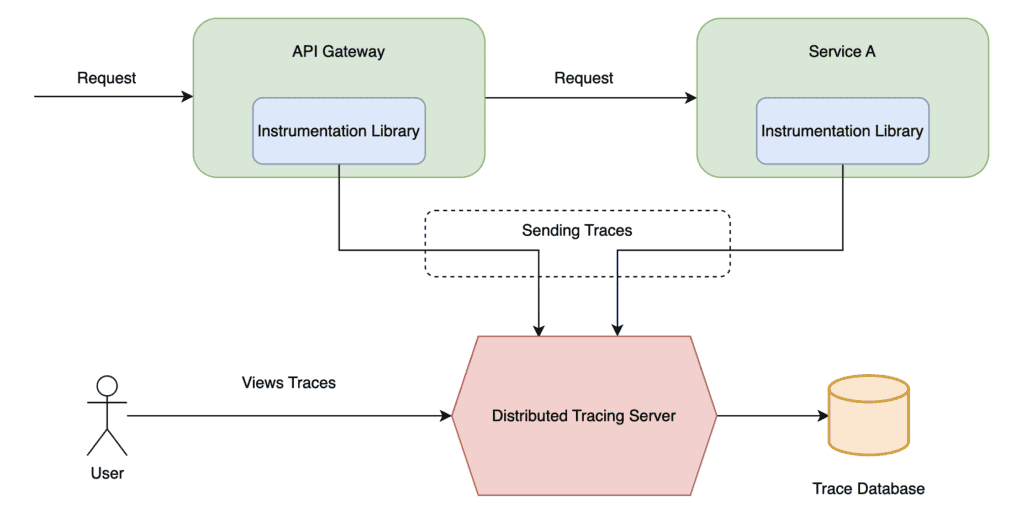
在探索分布式跟踪之前,我们必须定义两个关键概念:跟踪(traces)和跨度(spans)。跟踪表示外部请求,由一组跨度组成。跨度表示操作;其关键属性是操作名称、开始时间和结束时间。跨度可以有一个或多个表示嵌套操作的子跨度。
现在,让我们探索分布式跟踪的关键组件:检测库和分布式跟踪服务器。每个服务使用的检测库主要用于生成和传播跟踪数据,这涉及捕获服务中的操作细节,例如处理传入请求、对其他服务或数据库进行出站调用以及处理数据。
另一方面,分布式跟踪服务器是跟踪数据管理的中央枢纽。它提供从检测库接收跟踪数据的API,聚合和存储数据,并提供用于分析、监控和故障排除的工具。
下图展示了分布式跟踪的工作原理以及组件之间的交互:
3. Zipkin
Zipkin是一个领先的开源分布式跟踪系统,最初由Twitter开发。它旨在帮助收集解决微服务架构中的延迟问题所需的数据,它从已检测的服务中收集数据,然后提供这些数据的详细视图。
Zipkin由四个主要组件组成,我们将在以下小节中详细介绍每个组件。
3.1 收集器
当被检测的服务生成跟踪数据时,需要进行收集和处理。因此,收集器负责接收和验证Zipkin收到的跟踪。跟踪验证后,它们将被存储以供以后检索和分析。收集器可以通过HTTP或AMQP接收数据,使其灵活且适用于各种系统架构。
3.2 储存
Zipkin最初是使用Cassandra来存储数据的,因为它具有高度可扩展性、灵活性,并且在Twitter内部被广泛使用。但是,Zipkin已更新为更易于配置,支持其他存储选项,例如ElasticSearch、MySQL,甚至内存存储。
3.3 API
数据存储后,Zipkin通过RESTful接口提供直观的数据提取方法。此接口使我们能够根据需要轻松定位和检索跟踪。此外,API是Zipkin Web UI的支柱,而Zipkin Web UI是其主要数据源。
3.4 Web界面
Zipkin提供的图形用户界面(GUI)是一种基于服务、时间和注释检查跟踪的可视化方法。此外,它允许我们深入研究特定跟踪,从而促进详细分析,这对于解决涉及分布式事务的复杂问题特别有用。
4. Brave
Brave是一个分布式跟踪仪表库,它拦截生产请求、收集时序数据并传播跟踪上下文。其主要目标是促进分布式系统内时序数据的关联,从而高效地排除延迟问题。
尽管Brave通常将跟踪数据发送到Zipkin服务器,但它可以通过第三方插件灵活地与Amazon X-Ray等其他服务集成。
Brave提供了一个与JRE6及以上版本兼容的无依赖跟踪器库,它提供了一个用于计时操作和使用描述性属性标记操作的基本API。该库还包含解析X-B3-TraceId标头的代码,进一步丰富了其功能。
虽然通常不需要直接实现跟踪代码,但用户可以利用Brave和Zipkin提供的现有工具。值得注意的是,JDBC、Servlet和Spring等常见跟踪场景的库随时可用、经过严格测试和基准测试。
对于那些处理遗留应用程序的人来说,Spring XML配置提供了一个无缝的跟踪设置,而不需要自定义代码。
用户可能还希望将跟踪ID集成到日志文件中或修改线程本地行为,在这种情况下,Brave提供的上下文库可与SLF4J等工具无缝集成。
5. 如何使用Brave
接下来,让我们构建一个简单的Java和Spring Boot应用程序并将其与Brave和Zipkin集成。
5.1 Zipkin Slim设置
首先,我们需要运行Zipkin服务器。为此,我们将使用Zipkin Slim,这是Zipkin的精简版本,体积更小,启动速度更快。它支持内存和Elasticsearch存储,但不支持通过Kafka或RabbitMQ进行消息传递。
Zipkin的官方仓库中记录了多种使用方法。此外,你还可以在我们关于使用Zipkin跟踪服务的文章中找到有关运行Zipkin服务器的更多方法。
为了简单起见,我们假设我们已经在本地机器上安装了Docker,并使用以下命令运行它:
docker run -d -p 9411:9411 openzipkin/zipkin-slim
现在,通过访问http://localhost:9411/zipkin/,我们可以看到Zipkin Web UI。
5.2 项目设置
我们将从一个空的Spring Boot项目开始,其中包含brave、zipkin-reporter、zipkin-sender-okhttp3和zipkin-reporter-brave依赖项:
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave</artifactId>
<version>6.0.2</version>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-sender-okhttp3</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
<version>3.3.0</version>
</dependency>
接下来,我们需要一个配置类来实例化Tracer Bean,以便稍后使用它:
@Configuration
public class TracingConfiguration {
@Bean
BytesMessageSender sender() {
return OkHttpSender.create("http://127.0.0.1:9411/api/v2/spans");
}
@Bean
AsyncZipkinSpanHandler zipkinSpanHandler(BytesMessageSender sender) {
return AsyncZipkinSpanHandler.create(sender);
}
@Bean
public Tracing tracing(AsyncZipkinSpanHandler zipkinSpanHandler) {
return Tracing.newBuilder()
.localServiceName("Dummy Service")
.addSpanHandler(zipkinSpanHandler)
.build();
}
@Bean
public Tracer tracer(Tracing tracing) {
return tracing.tracer();
}
}
现在,我们可以将Tracer直接注入到我们的Bean中。为了演示,我们将创建一个虚拟服务,该服务将在初始化后向Zipkin发送跟踪:
@Service
public class TracingService {
private final Tracer tracer;
public TracingService(Tracer tracer) {
this.tracer = tracer;
}
@PostConstruct
private void postConstruct() {
Span span = tracer.nextSpan().name("Hello from Service").start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
span.finish();
}
}
}
如果运行我们的应用程序并检查Zipkin Web UI,我们应该能够看到我们的跟踪,只包含1个跨度,大约需要2秒:
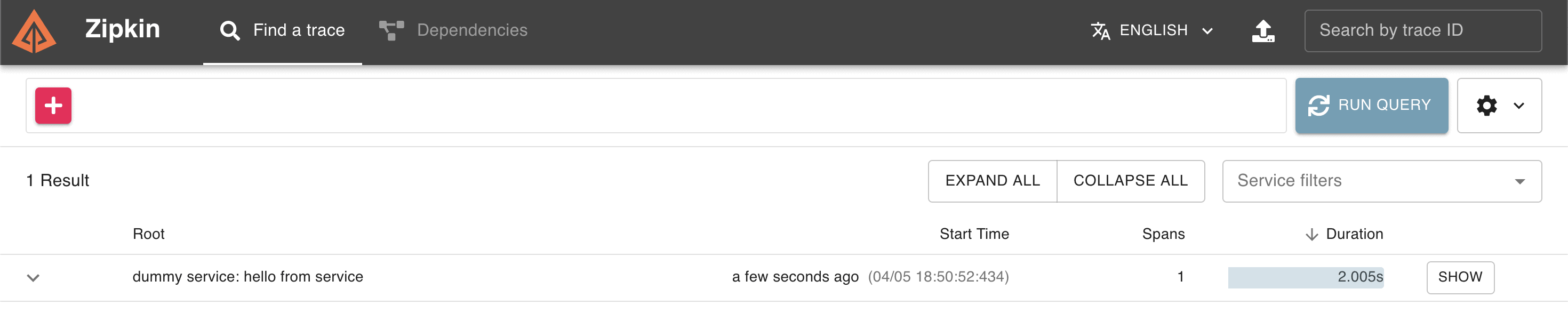
请注意,此示例仅简单配置了跟踪。处理更复杂的场景时,建议改用Spring Cloud Sleuth。
此外,brave-example仓库描述了跟踪简单Web应用程序的其他方法。
5. 总结
正如我们在本文中了解到的,Brave可帮助我们有效地监控应用程序。Brave简化了检测过程,并凭借与Zipkin的无缝集成,成为分布式系统中的宝贵资产。
Post Directory
