1. 概述
在本文中,我们将看到虚假共享有时如何使多线程对我们不利。
首先,我们将从缓存和空间局部性理论开始。然后我们将重写LongAdder并发实用程序并根据java.util.concurrent实现对其进行基准测试。在整篇文章中,我们将使用不同级别的基准测试结果来研究虚假共享的影响。
文章中与Java相关的部分很大程度上取决于对象的内存布局。由于这些布局细节不是JVM规范的一部分,而是由实现者自行决定,因此我们将只关注一种特定的JVM实现:HotSpot JVM。我们还可能在整篇文章中互换使用JVM和HotSpot JVM术语。
2. 缓存行和一致性
处理器使用不同级别的缓存-当处理器从主内存读取一个值时,它可能会缓存该值以提高性能。
事实证明,大多数现代处理器不仅会缓存请求的值,还会缓存更多附近的值。这种优化基于空间局部性的思想,可以显著提高应用程序的整体性能。简而言之,处理器缓存根据缓存行而不是单个可缓存值来工作。
当多个处理器在相同或附近的内存位置上运行时,它们最终可能会共享相同的缓存行。在这种情况下,必须使不同核心中的重叠缓存保持一致。保持这种一致性的行为称为缓存一致性。
有很多协议可以保持CPU核心之间的缓存一致性。在本文中,我们将讨论MESI协议。
2.1 MESI协议
在MESI协议中,每个缓存行都可以处于以下四种不同状态之一:修改、独占、共享或无效。MESI一词是这些状态的首字母缩写词。
为了更好地理解此协议的工作原理,让我们来看一个例子。假设两个核心要从附近的内存位置读取:
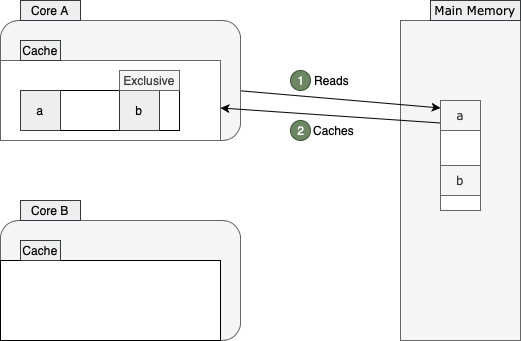
核心A从主存中读取a的值。如上所示,该核心从内存中获取更多值并将它们存储到缓存行中。然后它将该缓存行标记为exclusive,因为核心A是唯一在该缓存行上运行的核心。从现在开始,如果可能,该核心将通过从缓存行中读取来避免低效的内存访问。
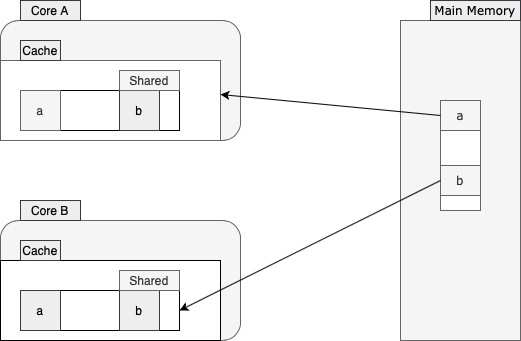
过了一会儿,核心B也决定从主存中读取b的值:
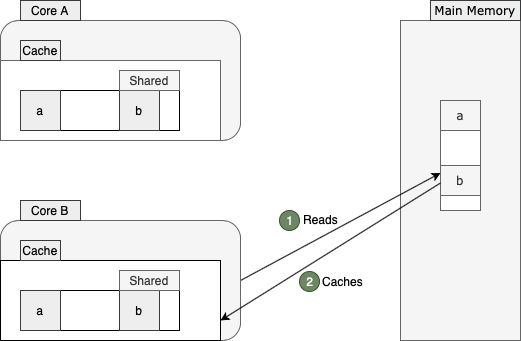
由于a和b彼此非常接近并且驻留在同一缓存行中,因此两个核心都将其缓存行标记为shared。
现在,假设核心A决定更改a的值:
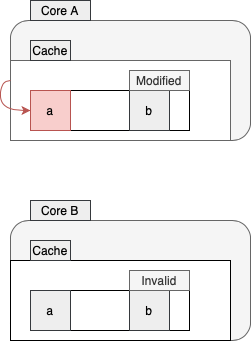
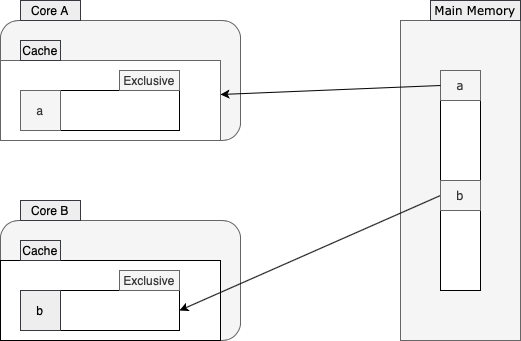
核心A仅将此更改存储在其存储缓冲区中,并将其缓存行标记为已修改。此外,它将此更改传达给核心B,而该核心又会将其缓存行标记为无效。
这就是不同处理器如何确保它们的缓存彼此一致的方式。
3. 虚假共享
现在,让我们看看当核心B决定重新读取b的值时会发生什么。由于这个值最近没有改变,我们可能期望从缓存行中快速读取。然而,共享多处理器架构的本质使这种期望在现实中无效。
如前所述,整个缓存行在两个核心之间共享。由于核心B的缓存行现在无效,它应该再次从主内存中读取值b:
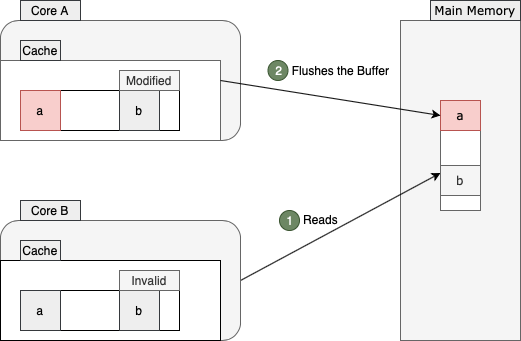
如上所示,从主内存读取相同的b值并不是这里唯一的低效率。这种内存访问将迫使核心A刷新其存储缓冲区,因为核心B需要获取最新值。刷新并获取值后,两个核心将再次以shared状态标记的最新缓存行版本结束:
因此,这会对一个核心造成高速缓存未命中,并对另一个核心造成早期缓冲区刷新,即使这两个核心没有在同一内存位置上运行。这种称为虚假共享的现象会损害整体性能,尤其是在高速缓存未命中率很高的情况下。更具体地说,当这个速率很高时,处理器将不断地访问主内存,而不是从缓存中读取。
4. 示例:动态条带化
为了演示虚假共享如何影响应用程序的吞吐量或延迟,我们将在本节中作弊。让我们定义两个空类:
abstract class Striped64 extends Number {
}
public class LongAdder extends Striped64 implements Serializable {
}
当然,空类没那么有用,所以让我们复制粘贴一些逻辑到其中。
对于我们的Striped64类,我们可以复制java.util.concurrent.atomic.Striped64类中的所有内容并将其粘贴到我们的类中。请确保也复制import语句。此外,如果使用Java 8,我们应该确保将对sun.misc.Unsafe.getUnsafe()方法的任何调用替换为自定义方法:
private static Unsafe getUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
我们不能从我们的应用程序类加载器调用sun.misc.Unsafe.getUnsafe(),所以我们不得不再次使用这个静态方法作弊。然而,从Java 9开始,相同的逻辑是使用VarHandles实现的,因此我们不需要在那里做任何特殊的事情,只需一个简单的复制粘贴就足够了。
对于LongAdder类,让我们从java.util.concurrent.atomic.LongAdder类中复制所有内容并将其粘贴到我们的类中。同样,我们也应该复制import语句。
现在,让我们对这两个类进行基准测试:我们的自定义LongAdder和java.util.concurrent.atomic.LongAdder。
4.1 基准测试
为了对这些类进行基准测试,让我们编写一个简单的JMH基准测试:
@State(Scope.Benchmark)
public class FalseSharing {
private java.util.concurrent.atomic.LongAdder builtin = new java.util.concurrent.atomic.LongAdder();
private LongAdder custom = new LongAdder();
@Benchmark
public void builtin() {
builtin.increment();
}
@Benchmark
public void custom() {
custom.increment();
}
}
如果我们在吞吐量基准测试模式下使用2个fork和16个线程运行此基准测试(相当于传递“–-bm thrpt -f 2 -t 16”参数),那么JMH将打印以下统计信息:
Benchmark Mode Cnt Score Error Units
FalseSharing.builtin thrpt 40 523964013.730 ± 10617539.010 ops/s
FalseSharing.custom thrpt 40 112940117.197 ± 9921707.098 ops/s
结果根本没有意义。JDK内置实现使我们的复制粘贴解决方案相形见绌,吞吐量增加了近360%。
让我们看看延迟之间的区别:
Benchmark Mode Cnt Score Error Units
FalseSharing.builtin avgt 40 28.396 ± 0.357 ns/op
FalseSharing.custom avgt 40 51.595 ± 0.663 ns/op
如上所示,内置解决方案还具有更好的延迟特性。
为了更好地理解这些看似相同的实现有何不同,让我们检查一些低级性能监控计数器。
5. 性能事件
为了检测低级CPU事件,例如周期、停顿周期、每个周期的指令、高速缓存加载/未命中或内存加载/存储,我们可以在处理器上对特殊的硬件寄存器进行编程。
事实证明,像perf或eBPF这样的工具已经在使用这种方法来公开有用的指标。从Linux 2.6.31开始,perf是标准的Linux分析器,能够公开有用的性能监控计数器或PMC。
因此,我们可以使用perf事件来查看在运行这两个基准测试中的每一个时在CPU级别发生了什么。例如,如果我们运行:
perf stat -d java -jar benchmarks.jar -f 2 -t 16 --bm thrpt custom
Perf将使JMH针对复制粘贴的解决方案运行基准测试并打印统计数据:
161657.133662 task-clock (msec) # 3.951 CPUs utilized
9321 context-switches # 0.058 K/sec
185 cpu-migrations # 0.001 K/sec
20514 page-faults # 0.127 K/sec
0 cycles # 0.000 GHz
219476182640 instructions
44787498110 branches # 277.052 M/sec
37831175 branch-misses # 0.08% of all branches
91534635176 L1-dcache-loads # 566.227 M/sec
1036004767 L1-dcache-load-misses # 1.13% of all L1-dcache hits
L1-dcache-load-misses字段表示L1数据缓存的缓存未命中数。如上所示,此解决方案遇到了大约10亿次缓存未命中(准确地说是1,036,004,767次)。如果我们为内置方法收集相同的统计数据:
161742.243922 task-clock (msec) # 3.955 CPUs utilized
9041 context-switches # 0.056 K/sec
220 cpu-migrations # 0.001 K/sec
21678 page-faults # 0.134 K/sec
0 cycles # 0.000 GHz
692586696913 instructions
138097405127 branches # 853.812 M/sec
39010267 branch-misses # 0.03% of all branches
291832840178 L1-dcache-loads # 1804.308 M/sec
120239626 L1-dcache-load-misses # 0.04% of all L1-dcache hits
我们会看到,与自定义方法相比,它遇到的缓存未命中次数要少得多(120,239,626~1.2亿)。因此,大量缓存未命中可能是造成这种性能差异的罪魁祸首。
让我们更深入地研究LongAdder的内部表示,找出真正的罪魁祸首。
6. 回顾动态条带化
java.util.concurrent.atomic.LongAdder是一个具有高吞吐量的原子计数器实现。它不是只使用一个计数器,而是使用它们的数组来分配它们之间的内存争用。这样,它将在竞争激烈的应用程序中胜过简单的原子类,例如AtomicLong。
Striped64类负责分配内存争用,这就是此类实现这些计数器数组的方式:
@jdk.internal.vm.annotation.Contended
static final class Cell {
volatile long value;
// omitted
}
transient volatile Cell[] cells;
每个Cell封装了每个计数器的详细信息。这种实现使得不同的线程可以更新不同的内存位置。由于我们使用状态数组(即条带),因此这个想法称为动态条带化。有趣的是,Striped64是根据这个想法以及它适用于64位数据类型的事实命名的。
无论如何,JVM可能会在堆中将这些计数器分配到彼此附近。也就是说,其中一些计数器将位于同一缓存行中。因此,更新一个计数器可能会使附近计数器的缓存失效。
这里的关键是,动态条带化的天真实现会遭受虚假共享。但是,通过在每个计数器周围添加足够的填充,我们可以确保它们中的每一个都驻留在其缓存行中,从而防止虚假共享:
事实证明,@jdk.internal.vm.annotation.Contended注解负责添加此填充。
唯一的问题是,为什么这个注解在复制粘贴的实现中不起作用?
7. 认识@Contended
Java 8引入了sun.misc.Contended注解(Java 9将其重新打包到jdk.internal.vm.annotation包下)来防止虚假共享。
基本上,当我们用这个注解来标注一个字段时,HotSpot JVM会在在标注的字段周围添加一些填充。这样,它可以确保该字段驻留在它自己的缓存行中。此外,如果我们用这个注解来标注整个类,HotSpot JVM将在所有字段之前添加相同的填充。
@Contended注解旨在供JDK本身在内部使用。所以默认情况下,它不会影响非内部对象的内存布局。这就是我们复制粘贴的加法器性能不如内置加法器的原因。
要删除此仅限内部的限制,我们可以在重新运行基准测试时使用-XX:-RestrictContended调优标志:
Benchmark Mode Cnt Score Error Units
FalseSharing.builtin thrpt 40 541148225.959 ± 18336783.899 ops/s
FalseSharing.custom thrpt 40 546022431.969 ± 16406252.364 ops/s
如上所示,现在基准测试结果更加接近,差异可能只是一点噪音。
7.1 填充大小
默认情况下,@Contended注解添加128个字节的填充。这主要是因为许多现代处理器中的高速缓存行大小约为64/128字节。
但是,此值可通过-XX:ContendedPaddingWidth调整标志进行配置。在撰写本文时,此标志仅接受0到8192之间的值。
7.2 禁用@Contended
也可以通过-XX:-EnableContended调整来禁用@Contended效果。当内存非常宝贵并且我们可以承受一点(有时是很多)性能损失时,这可能会被证明是有用的。
7.3 用例
在首次发布后,@Contended注解已被广泛使用,以防止JDK内部数据结构中的虚假共享。以下是此类实现的一些著名示例:
- Striped64类实现高吞吐量的计数器和累加器
- Thread类,有助于实现高效的随机数生成器
- ForkJoinPool任务,窃取队列
- ConcurrentHashMap实现
- Exchanger类中使用的双重数据结构
8. 总结
在本文中,我们了解了虚假共享有时如何对多线程应用程序的性能产生适得其反的影响。
为了更具体地说明问题,我们确实根据其副本对Java中的LongAdder实现进行了基准测试,并将其结果用作我们性能调查的起点。
此外,我们还使用perf工具收集了一些关于Linux上正在运行的应用程序的性能指标的统计数据。要查看更多perf示例,强烈建议阅读Branden Greg的博客。此外,从Linux核心版本4.4开始可用的eBPF也可用于许多跟踪和分析场景。
与往常一样,本教程的完整源代码可在GitHub上获得。
Post Directory
